I was inspired by @charnel_mouse’s analysis of the recent Codex tournament, and with some very helpful pointers from him, ran a similar analysis on all of our historical Yomi matches. My goal was to compute estimates of matchup numbers, taking into account all games played between the characters, and the skills of the players playing them.
To that end, I modeled the results of the matches using log odds of victory based on the difference in player skill plus the advantage for the first player based on the matchup. The player skill was computed per-tournament (but considered constant within a tournament), and was allowed to vary by a learned parameter between tournaments.
First, the matchup chart:
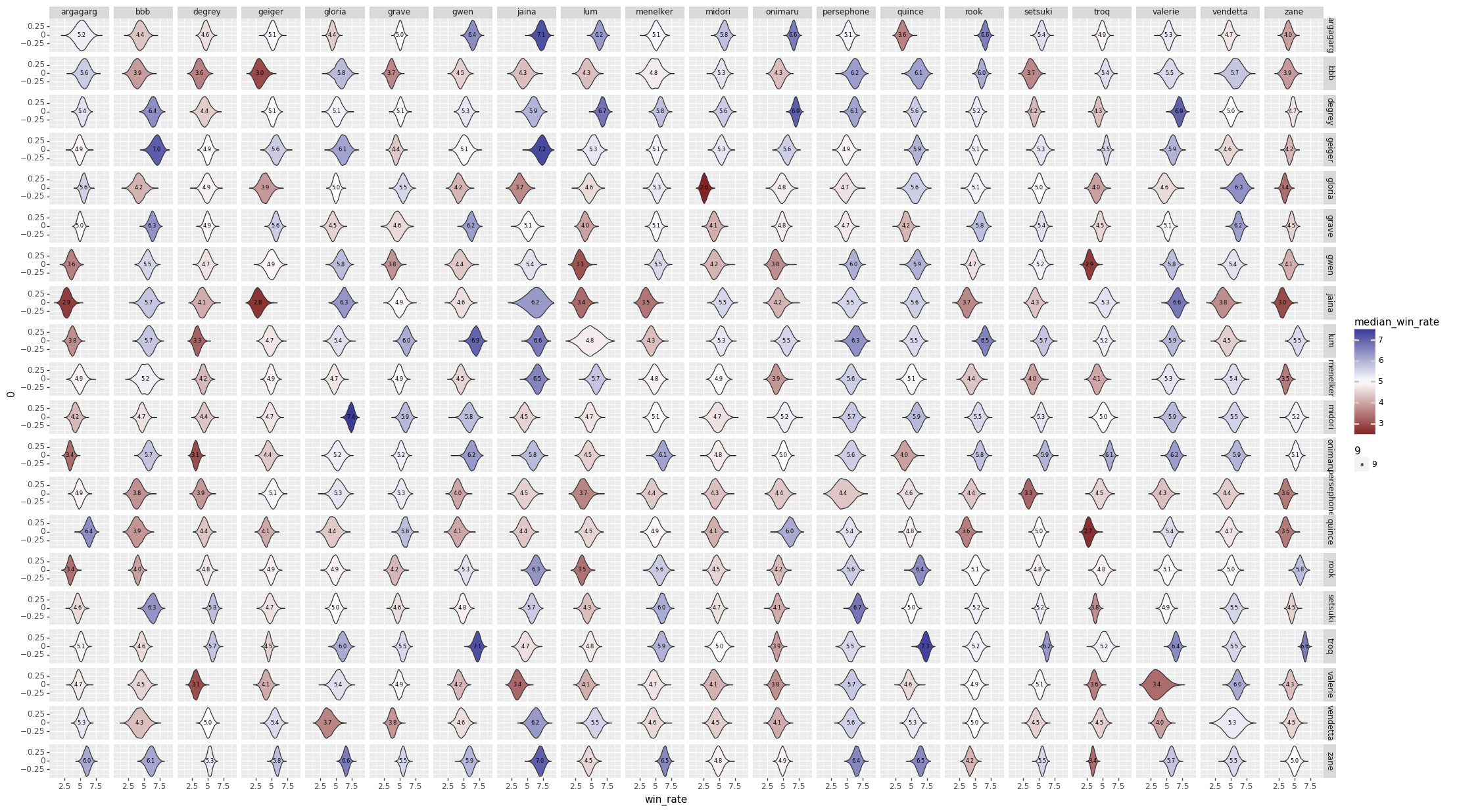
As usual, the rows are player 1, and the columns are player 2, so a box that is very blue favors the character labeled at the end of the row. Plots that are narrower indicate a higher confidence in the matchup number (due to either less variance in the matchup, more games played, or both).
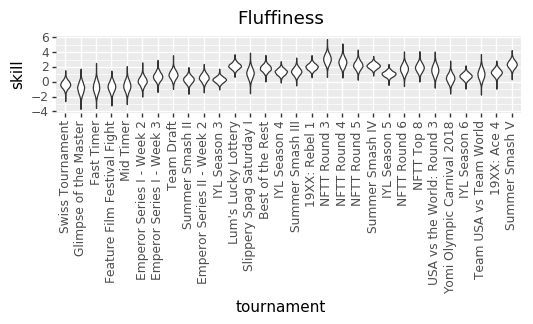
For skills, I don’t have a concise chart with everyone, but I’ll put a few examples so that you can see that the model learned something about player skill.
First, me!
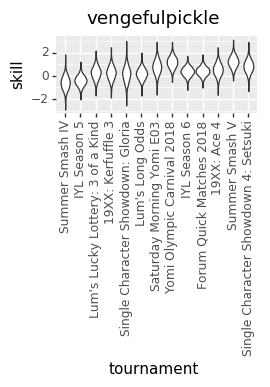
Then, the peoples champion, @mysticjuicer!

And finally, the storied career of the esteemed @cpat
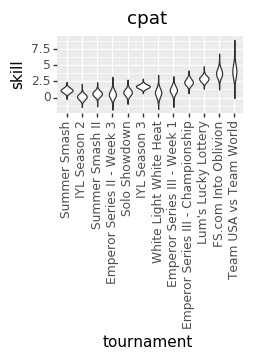
For reference on what those numbers mean, here’s a chart that @charnel_mouse through together when explaining the math to me:
| Matchup | Difference in Log odds |
|---|---|
| 1-9 | -2.20 |
| 2-8 | -1.39 |
| 3-7 | -0.85 |
| 4-6 | -0.41 |
| 5-5 | 0.00 |
| 6-4 | 0.41 |
| 7-3 | 0.85 |
| 8-2 | 1.39 |
| 9-1 | 2.20 |
So when you see @cpat clocking in at ~3.5 in his later tournaments, you can see just how far ahead he is over your average bear/new Yomi player.
 -loving heart was that this chart seems to run counter to the wisdom that she is a good counterpick to
-loving heart was that this chart seems to run counter to the wisdom that she is a good counterpick to  . Although, I suppose her matchup with him is at least better than the majority of the rest of her matchups…
. Although, I suppose her matchup with him is at least better than the majority of the rest of her matchups…
 -
-
 -
-
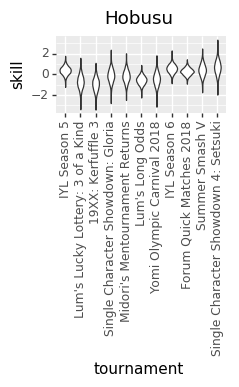
 , and
, and 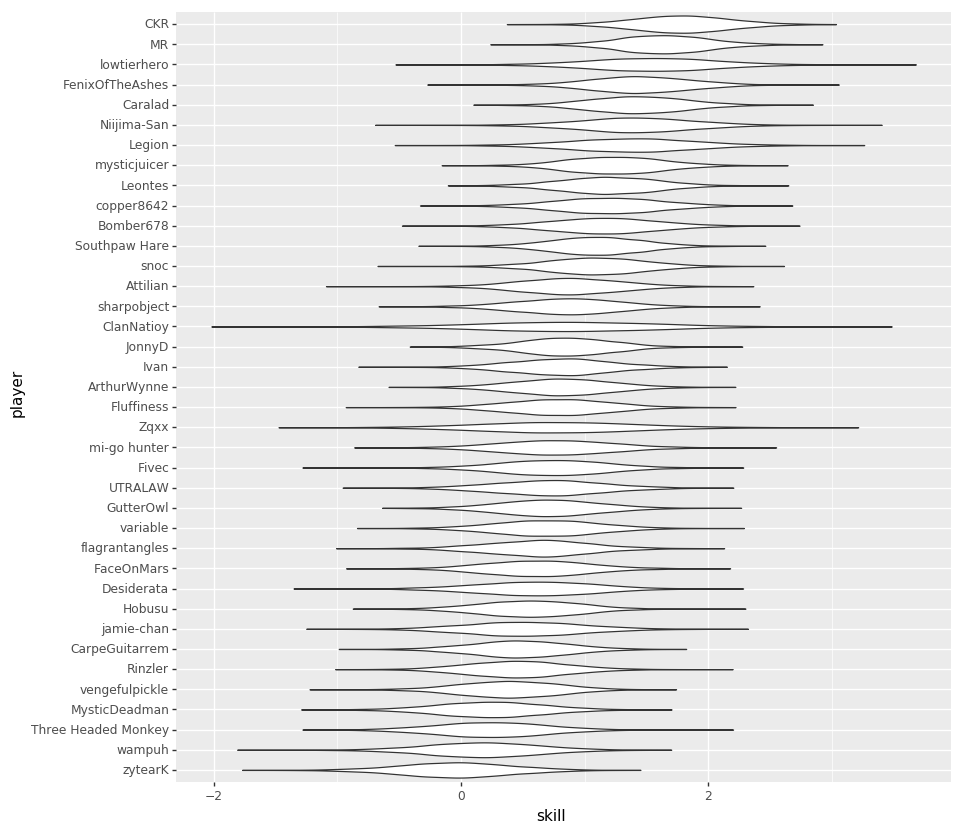

 (6.2) and
(6.2) and  (3.4). My first reaction was that these cases have pretty broad distributions indicating high variation, so I expect wide confidence intervals with no statistically significant deviation from 5.0. Part of me thinks that this could be ok, but we probably have to discount any result in with similar levels of variation since it can be as wrong as a true 5:5 being a 6:4 or 6.5:3.5.
(3.4). My first reaction was that these cases have pretty broad distributions indicating high variation, so I expect wide confidence intervals with no statistically significant deviation from 5.0. Part of me thinks that this could be ok, but we probably have to discount any result in with similar levels of variation since it can be as wrong as a true 5:5 being a 6:4 or 6.5:3.5. )
)

 You’re going to have to break things waaaaay down for me to follow any of this.
You’re going to have to break things waaaaay down for me to follow any of this.