Ok, lemme try and break this down.
The Setup
Let’s say we’re talking about a specific game, say between myself and @mysticjuicer. If we had perfect information, we might be able to say that I’ll win with some probability p. Conversely, juicer will win with probability 1-p. Because we know something about Yomi, we could say that p probably depends on my skill, juicer’s skill, the difficulty of the particular character matchup, plus some randomness based on the luck of the draw that particular game. The goal of this exercise is to figure out what each of those skills is, what the actual much number is, and approximately how impactful the randomness of the deck is.
So, we have something like:
p ~= skill(pickle) - skill(juicer) + matchup(pers, troq) + variance(pers, troq)
In order to make the math more tractible, we’ll instead use the formula:
ln(p/1-p) = skill(pickle) - skill(juicer) + matchup(pers, troq) + variance(pers, troq)
That natural log ln is what I was talking about earlier with the table of Difference of Log Odds.
The Analysis
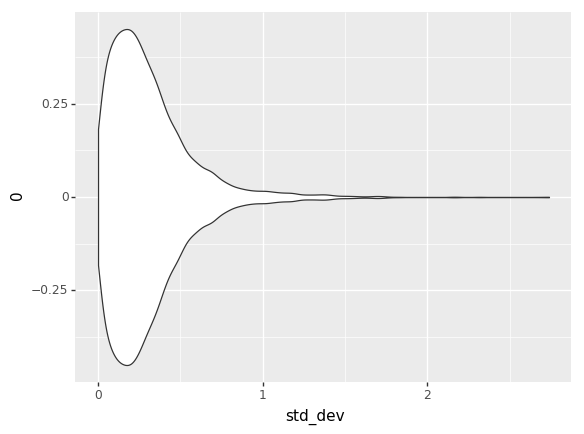
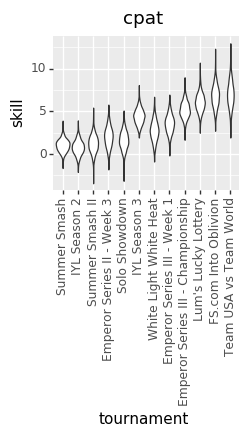
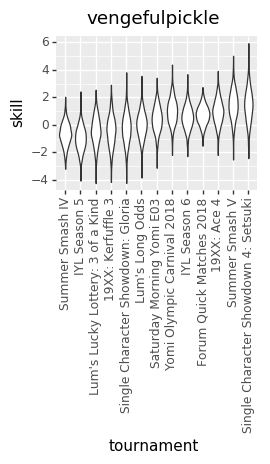
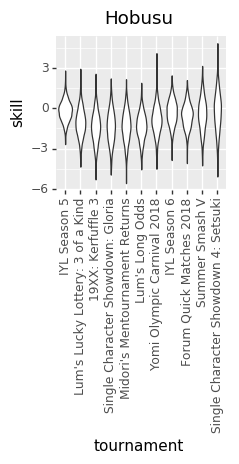
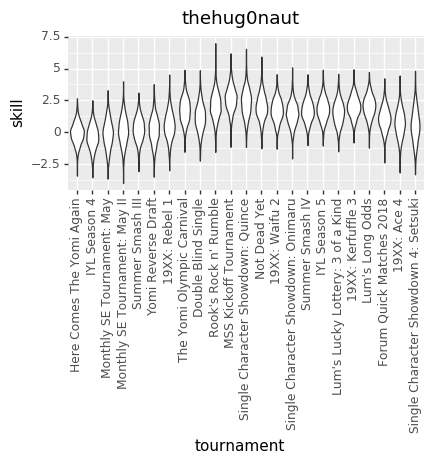
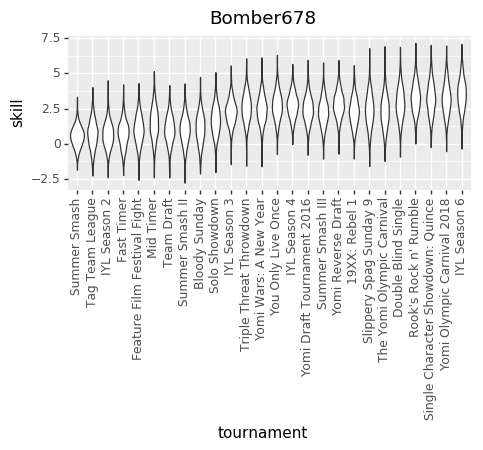
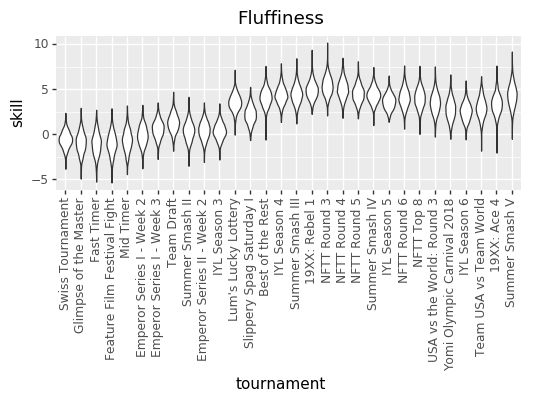
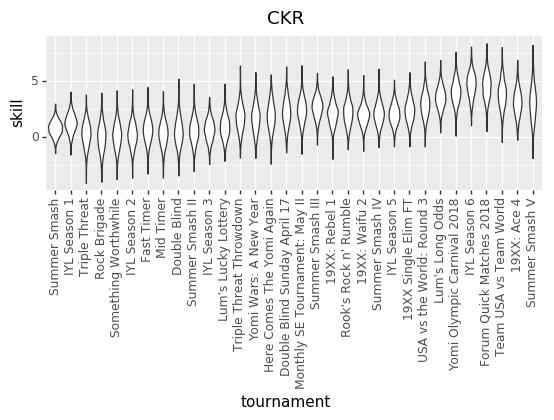
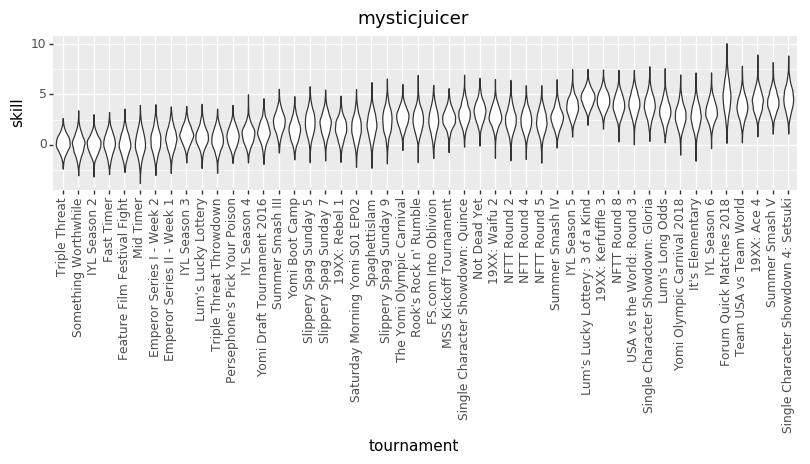
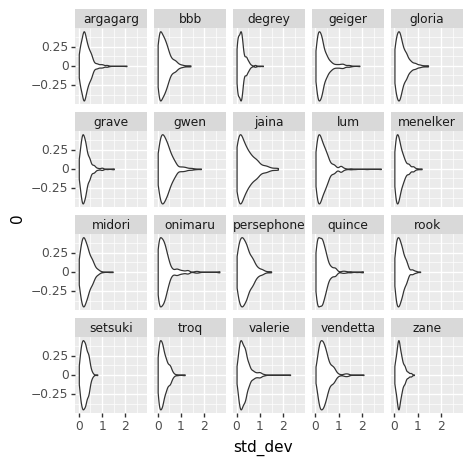
Because we don’t know the exact numbers, what we’re trying to do is estimate all of the skills (at points in time, across all players), matchup numbers, and variance amounts, by figuring out what values of those things best explain the actual outcomes we’ve seen in the Yomi historical data. We do that by basically taking a guess at all those parameters, seeing how well they explain the data, and then adjusting our guess at the parameters. Do that several thousand times and you end up with a bunch of parameter guesses. The graphs are charts of the number of times that we guessed each value for each parameter. The number in the middle of each graph is the median guess.
EDIT: The other relevant thing is that I converted The numbers in both charts out of log-odds space. That means, though, that each chart treats the other factors as irrelevant. That particularly affects the variance chart, where the same size variance in log-odds space will have different size effects on p based on (say) the matchup skew.