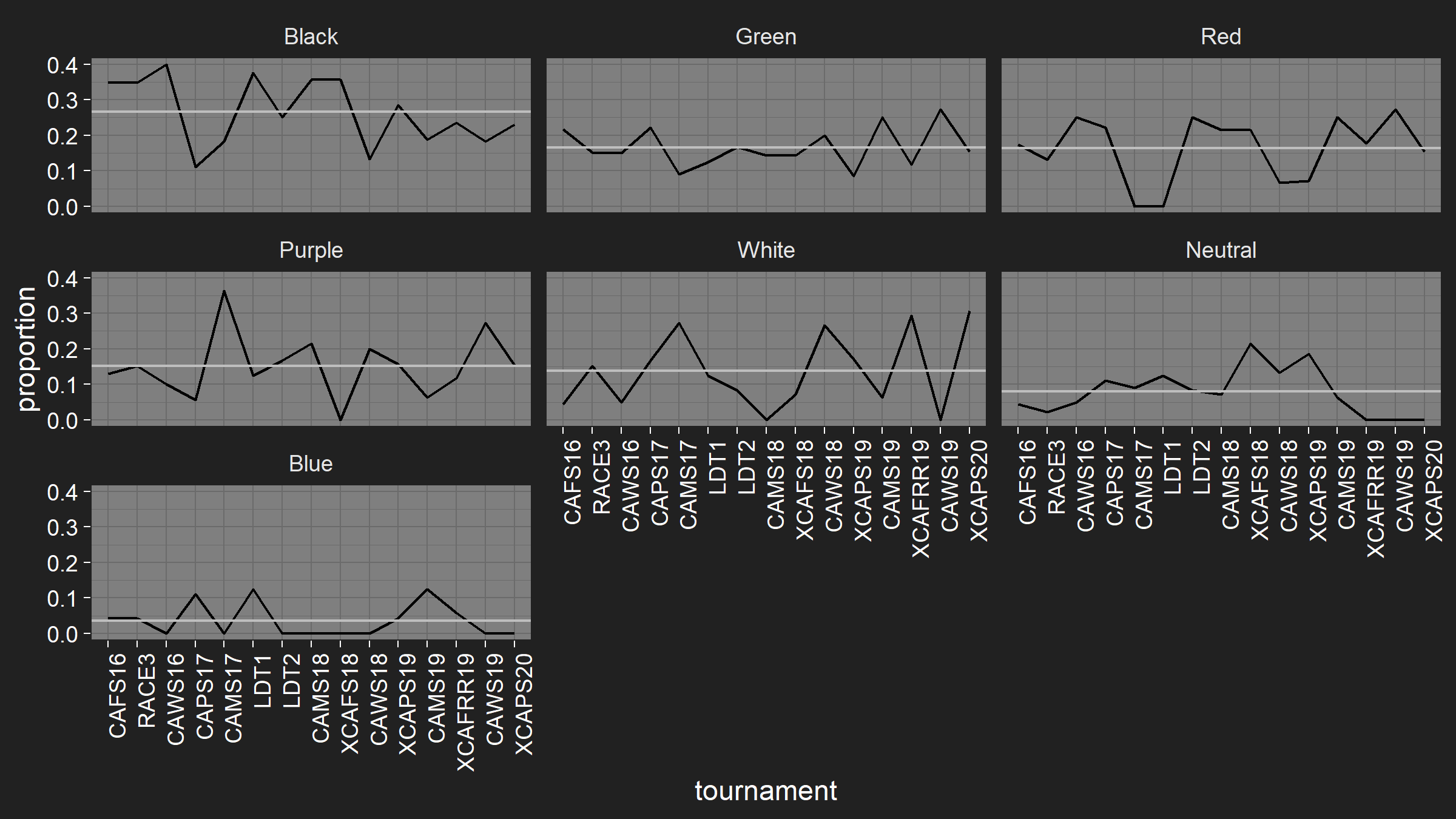
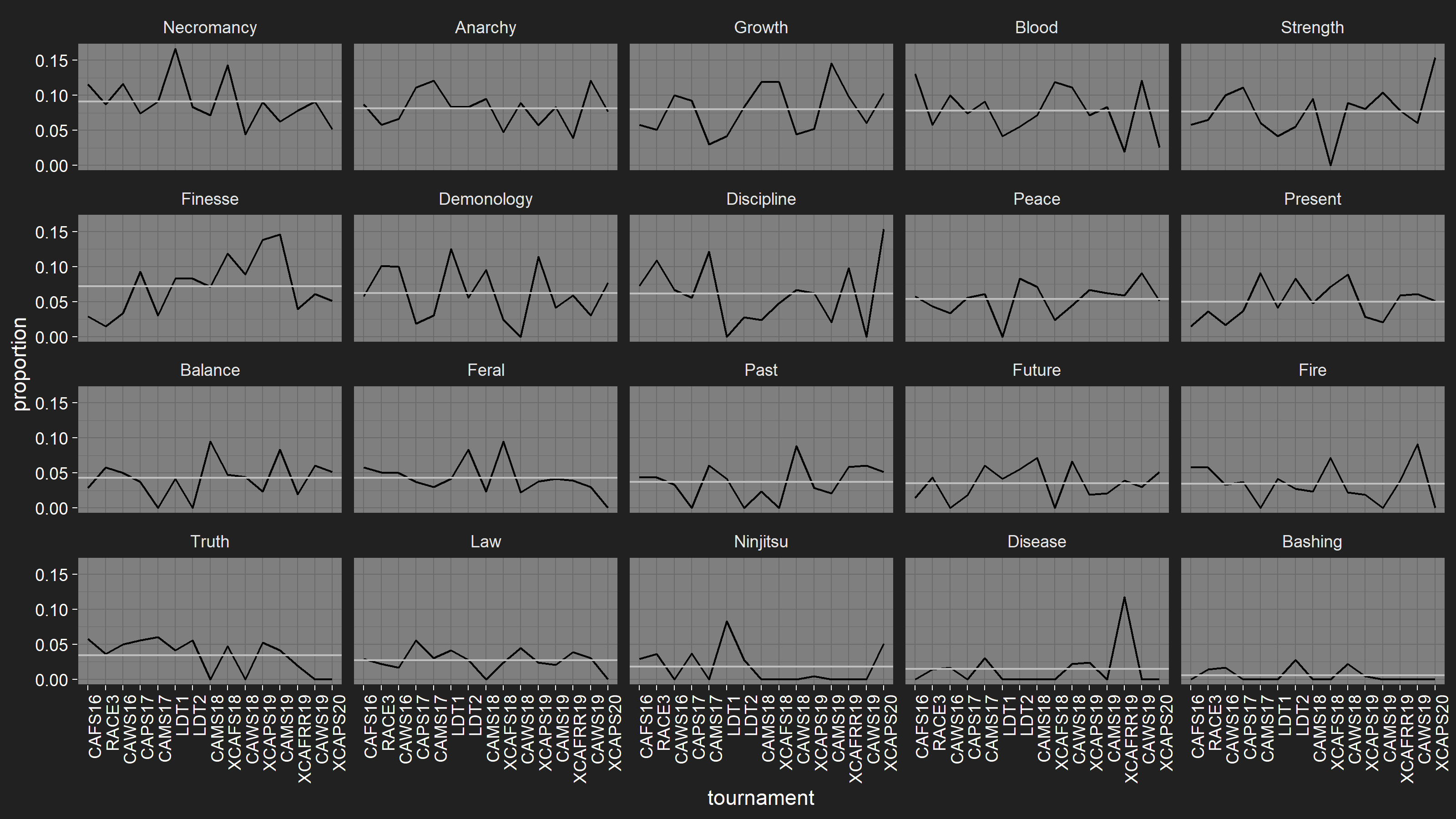
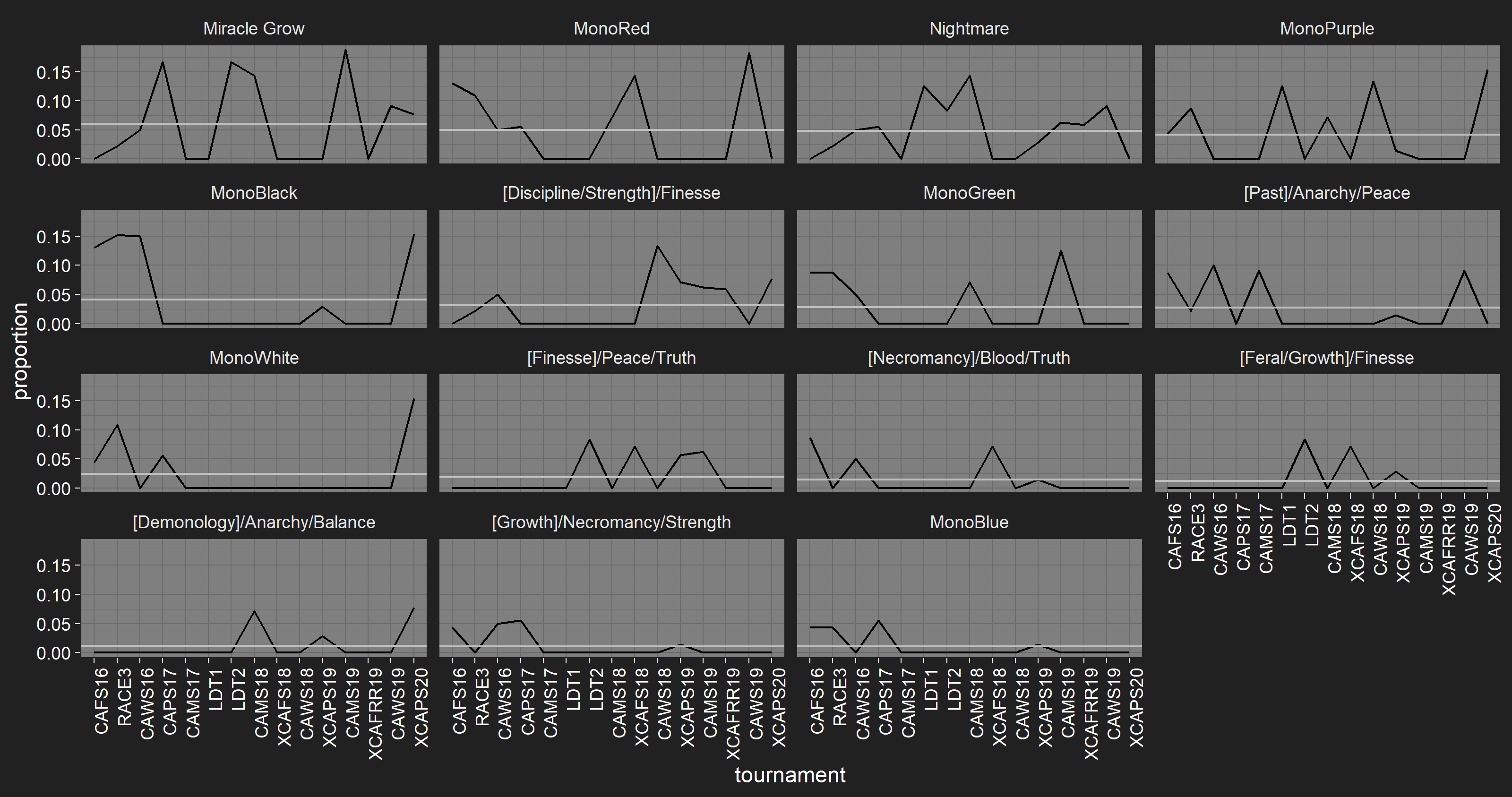
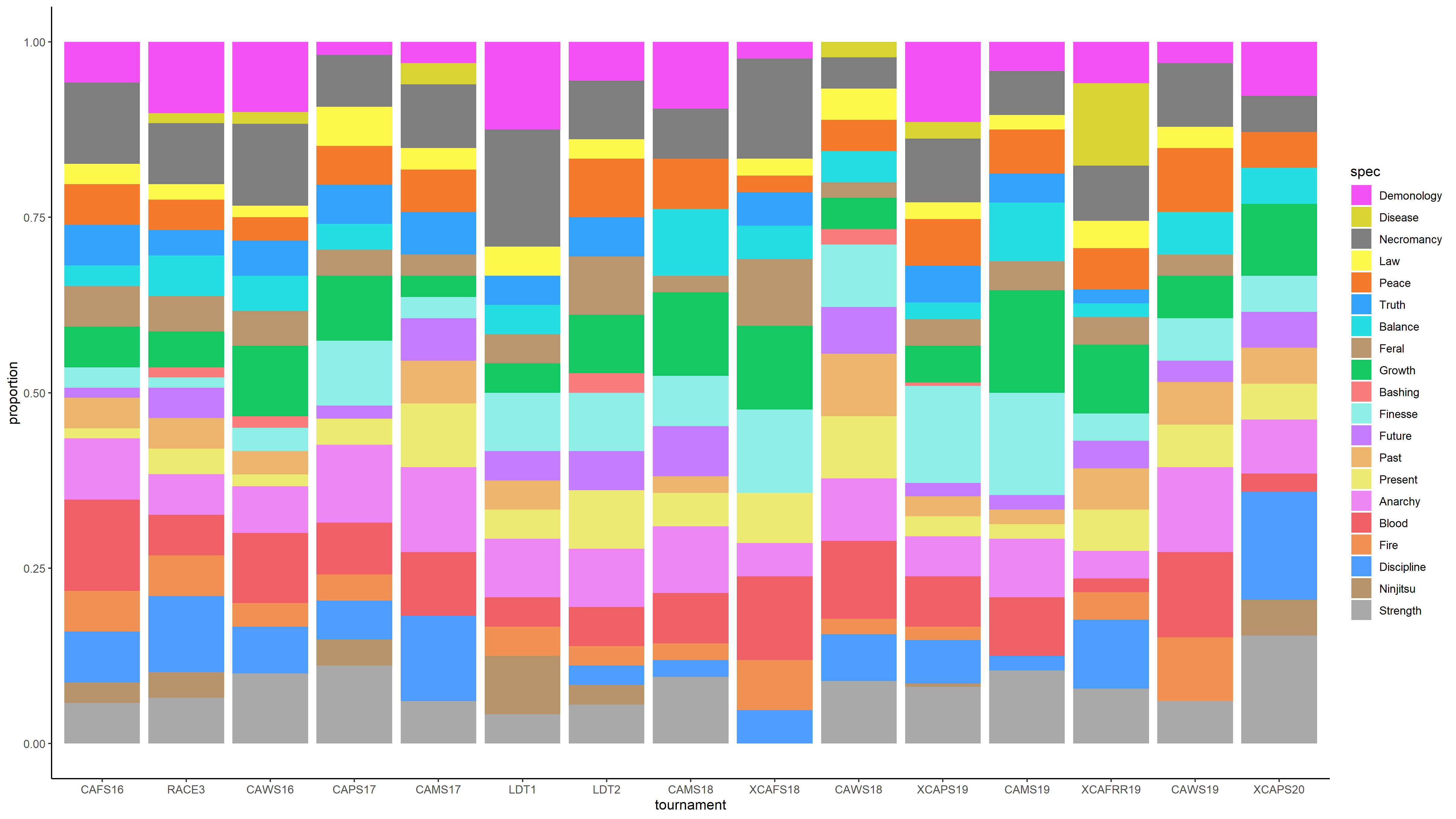
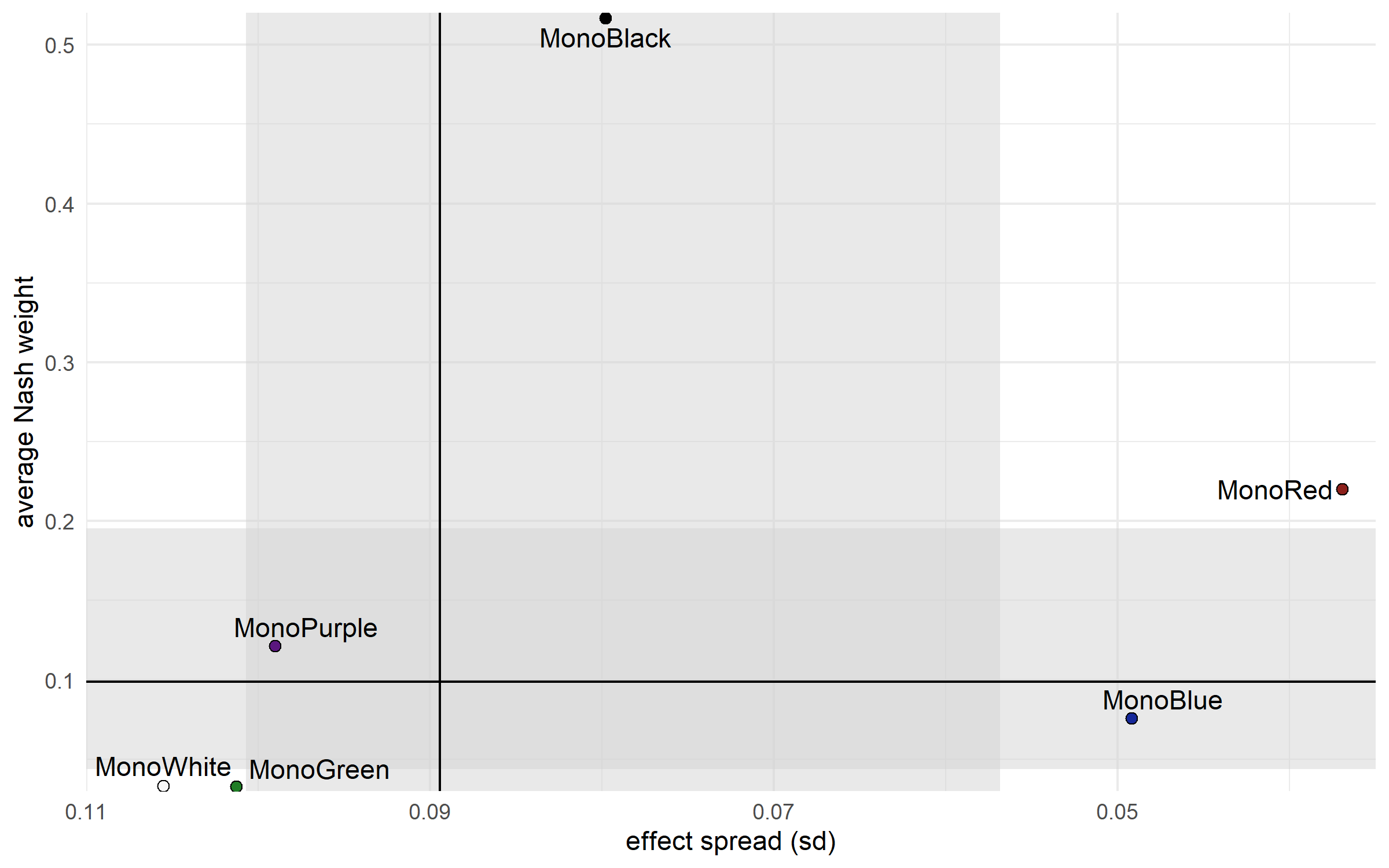
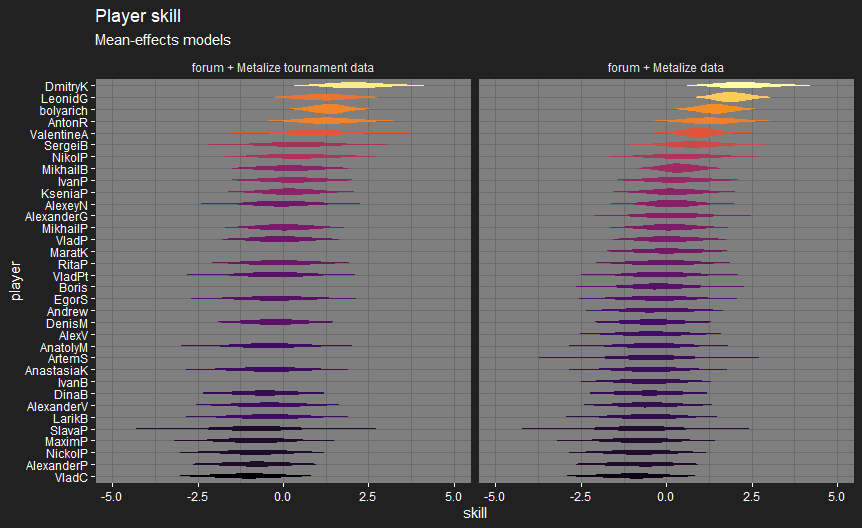
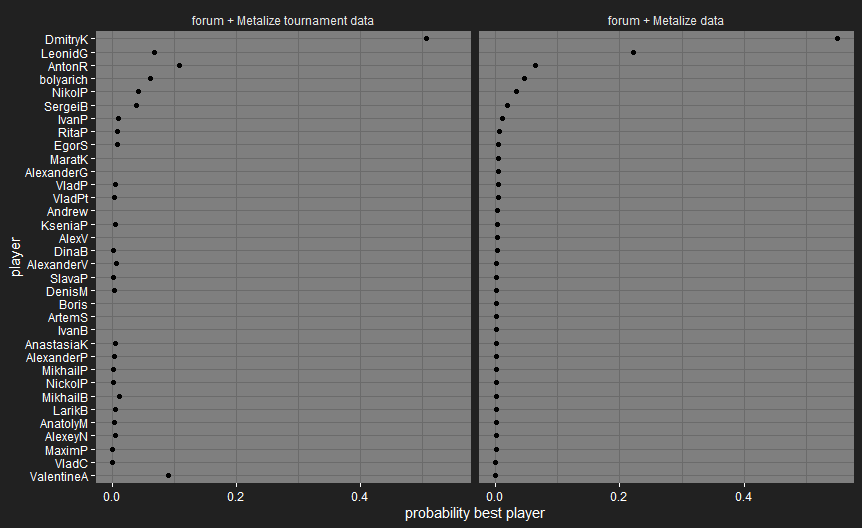
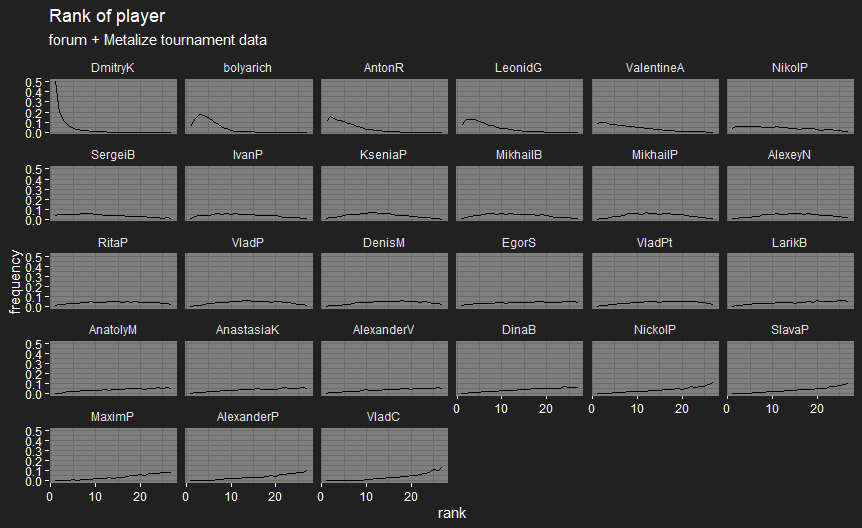
Just before I posted this, I realised I had a few matches where I’d recorded players with the wrong decks, so I had to go back and fix my automated data checks. It doesn’t seem to have changed the results much.
For those who are interested, I’ve split off the data, data checks, and deck name converters, into a separate module, and put it on Github here.
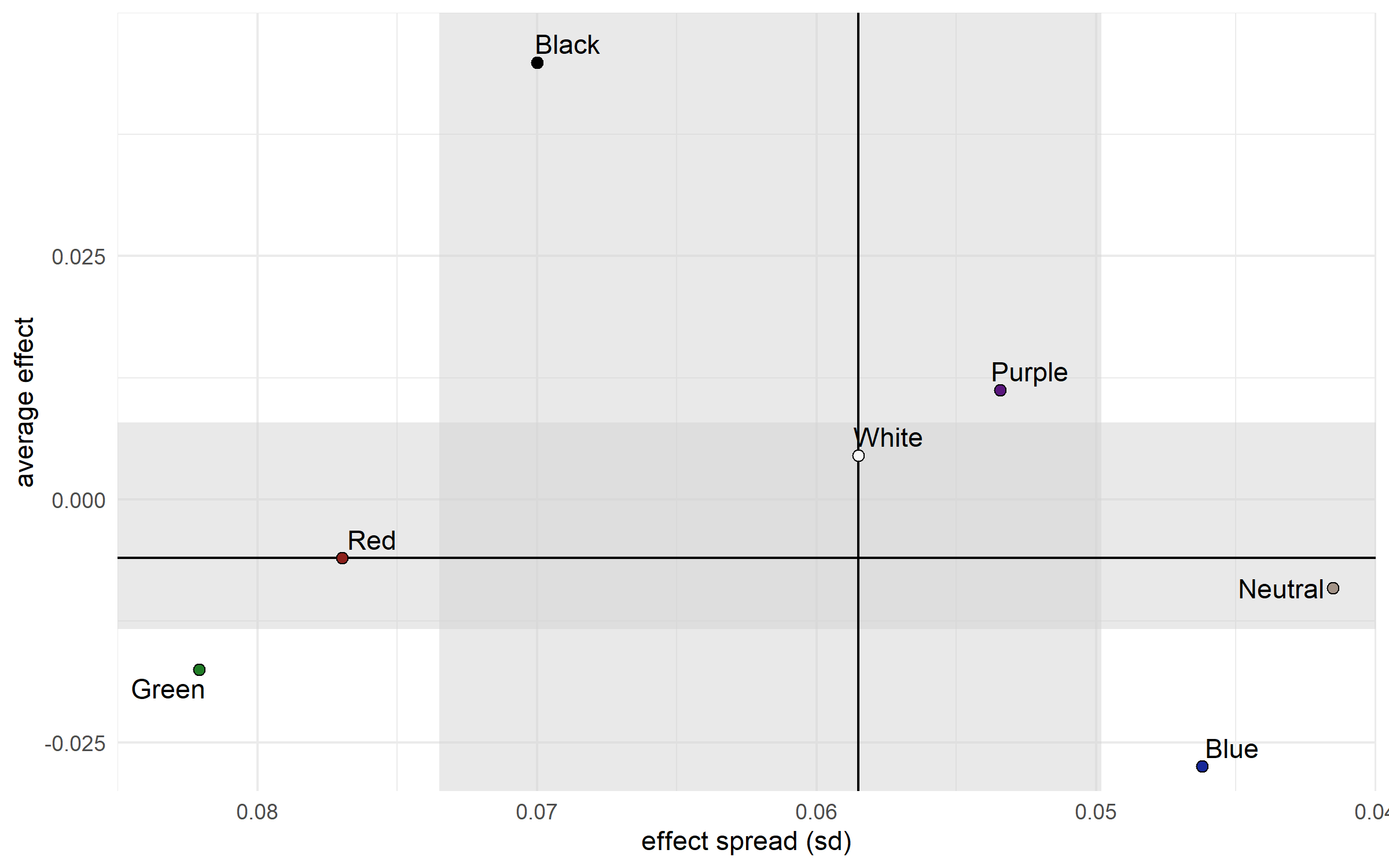
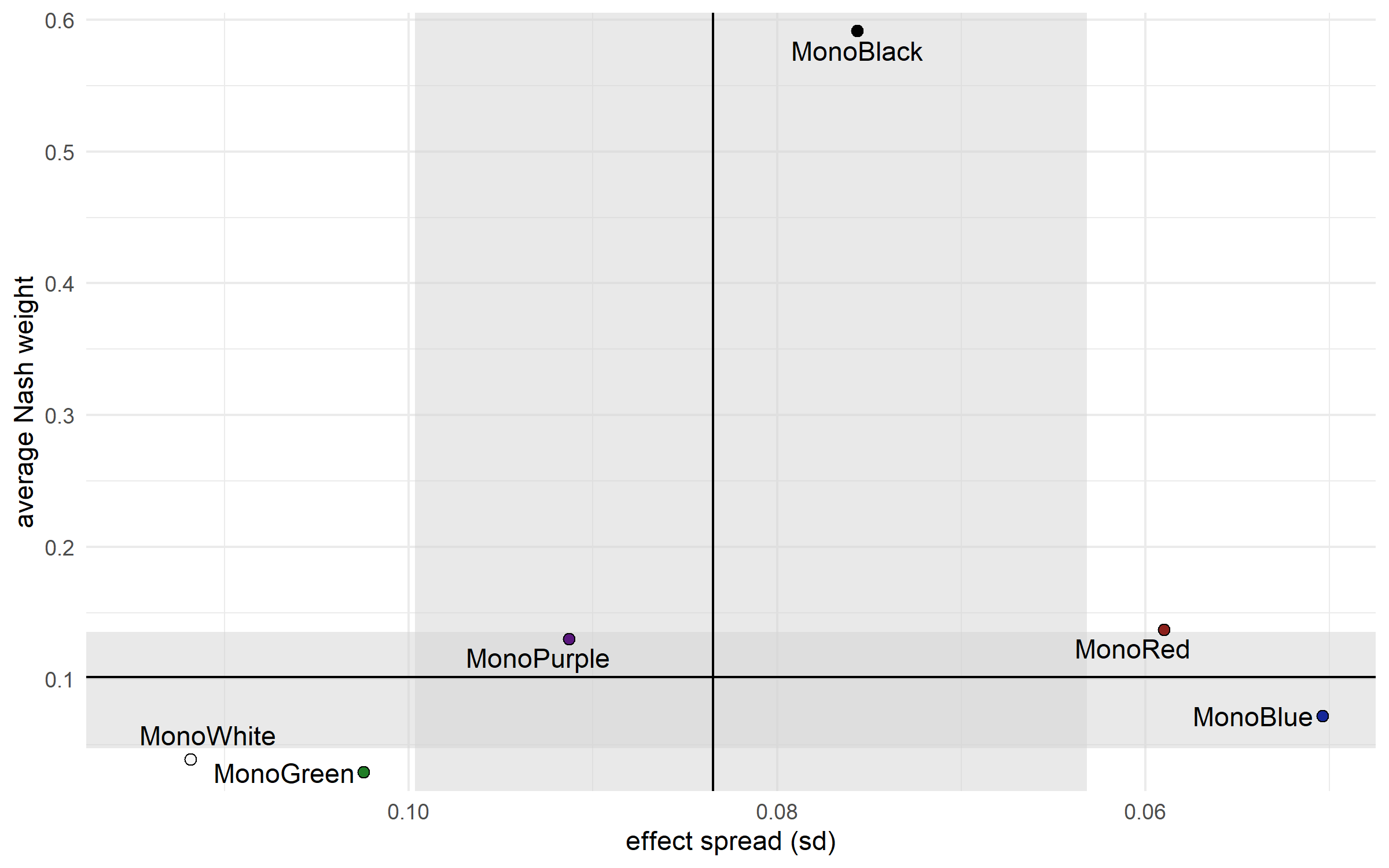
Calibration
We’re giving the win probability for Player 1 in each match, not just the favoured player. If the model thinks the match is 7-3, we expect to see Player 1 win 70% of those matches, not all of them.
This means that, on the plot giving P1 win probabilities, we expect the P2 wins to gradually become more common as the probability decreases, not a sharp cut-off at 50%.
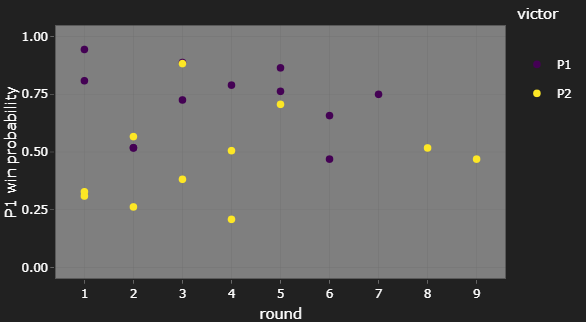
This is roughly what we see. That P2 victory at c. 85% P1 win probability in round 3 is an upset, sure, but we expect to see an few upsets at that probability level.
(If you’re wondering why round 2 only seems to have 3 matches, that purple dot in is actually two purple dots right on top of each other.)
The only thing I’d be concerned with here is that we don’t see any P1 wins at low probabilities. However, there weren’t many matches that favoured P2 anyway, so this might just be due to random chance, given the low sample size.
Match closeness in late tournament
One thing I’ve been interested in tracking on this tournament tracker is whether we see matches in later rounds being more fair, i.e. closer to 50% P1 win probability, as the field narrows to the most competitive player/deck pairings.
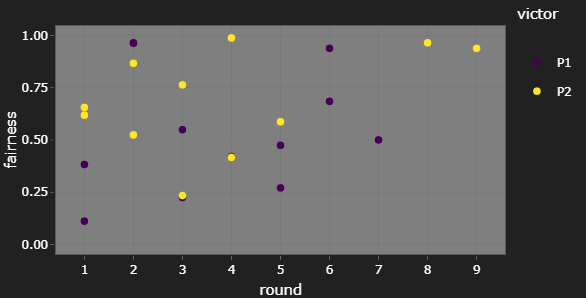
For CAMS20, I’m not really convinced this was the case. However, the number of matches seen at later rounds is always lower, so this could be to random chance too. To get a better idea of how fairness changes as a tournament goes on, I’d have to look at several tournaments at once, unless we get a tournament with several dozen players.
Brier score
Reminder: the Brier score is a number between 0 and 1; the smaller the Brier score, the better. It’s a proper scoring rule: if you knew the true result probability, you optimise your expected score by giving that true probability as your prediction. If you give a prediction of 5-5, you’re guaranteed a score of 0.25, so this is a good benchmark that your predictions should improve on.
On the evaluation page, I give both the observed Brier score, and the “prior expected score”: assuming the predictions are correct, what is the average score we’d expect to see? This assumes the matches are fixed, so ignores the fact that, if matches had ended differently, we’d see different matches later.
| forecast |
Brier score |
| always 5-5 |
0.250 |
| prior expected score |
0.194 |
| model |
0.173 |
The model is clearly doing better than flipping a coin. But how much better? I personally find it quite hard to tell when there are several models to compare, let alone when we’re looking at the score for a single model. Next time, I’m going to break the score up into more intuitive parts, and see whether that helps.
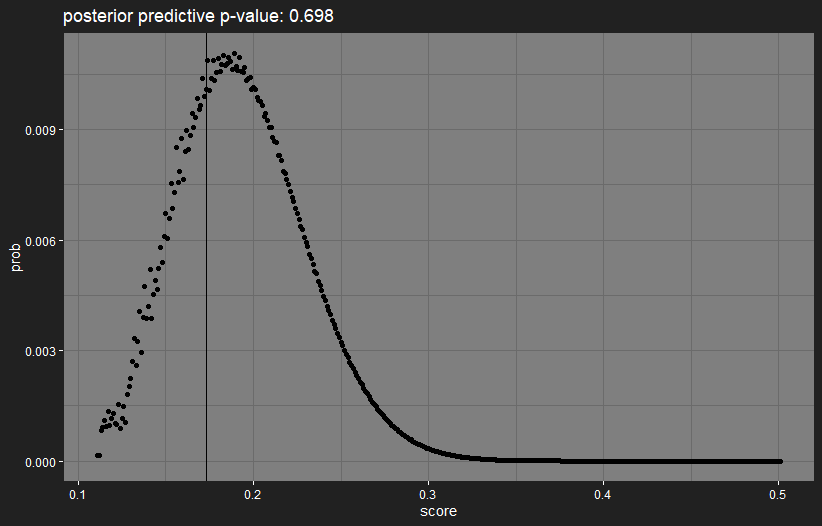
However, if we again assume that the model’s predictions are correct, we can look at how likely we are to see the observed score. If it turns out to be highly extreme, then the model is way off in its predictions. Since we can calculate the exact distribution of the score if the predictions are correct, we can plot the distribution, with a vertical line indicating the observed value:
The observed score is in a highly-likely region, so there’s no reason from this to think that the model is doing something badly wrong.
Current plans
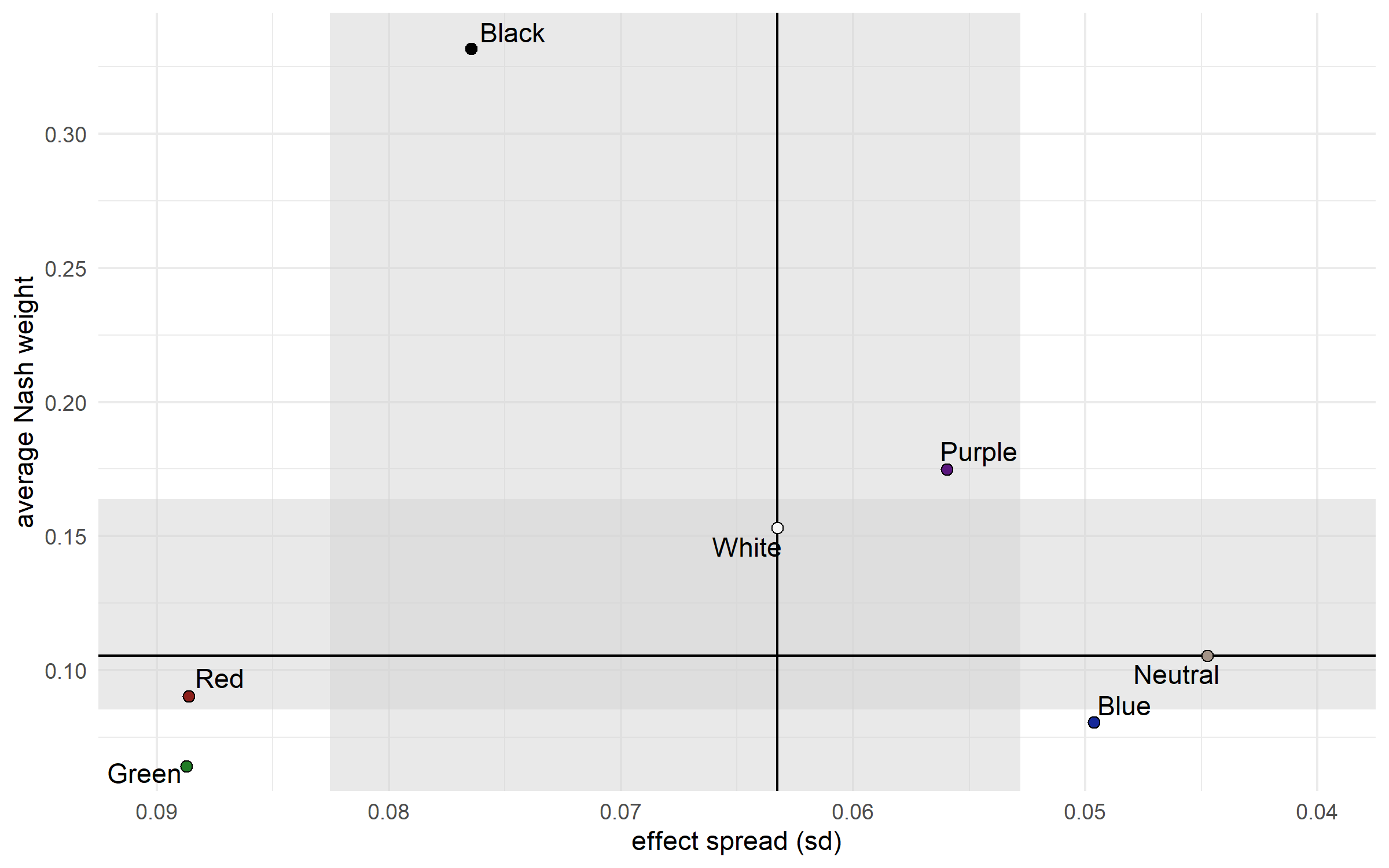
Still, I’m not quite happy with the model as it stands. There’s no accounting for synergies between starters/specs in a deck whatsoever, which should have a huge effect on a deck’s strength. The absence of synergies is probably why there are some odd results, like Nightmare and Miracle Grow not being considered especially great decks.
I’m looking to have a new model version that includes within-deck synergies by CAWS20. But first, I’ll be adding handling for the “new” starters/specs that will be appearing in XCAFS20. I won’t be doing predictions while it’s on, since there’s no starter/spec match history for the model to work with.