Maybe the model already hates Vandy, too.
2 Likes
A few more graphs before I take the time to account for spec choices. Again, just for CAMS 2018.
I added in effects for starter decks, given turn order.
I haven’t added effects for players’ proficiencies with their chosen decks, that’ll need data from multiple tournaments. Effectively, that means all players are assumed to be equally proficient with all starter decks.
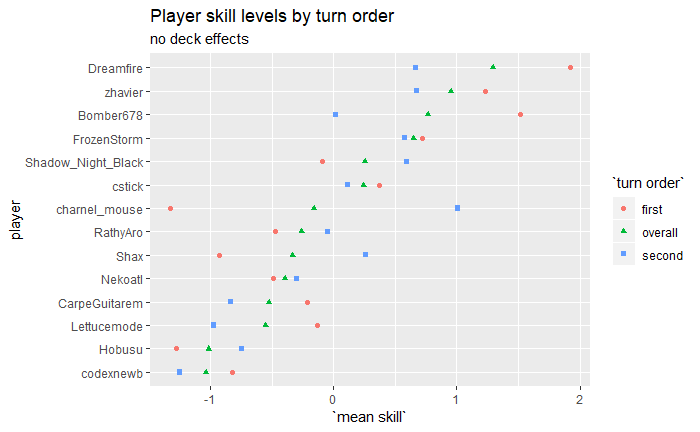

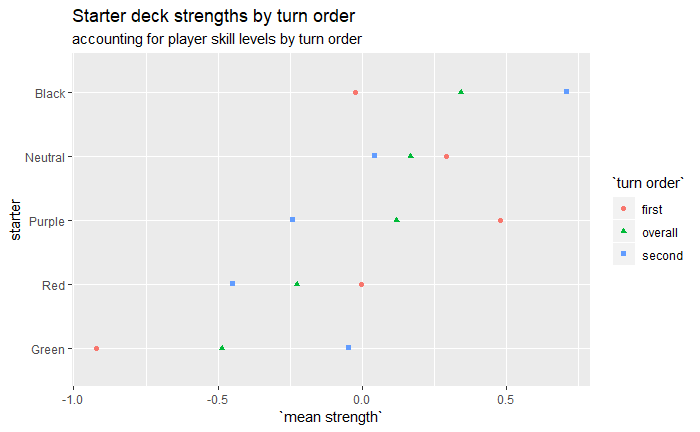
Lettucemode and Carpe come out with a higher skill due to playing MonoGreen and MonoRed, top player is closer between zhavier and Dreamfire. Purple does better for first player, which probably says more about the specs it was paired with rather than MonoPurple being better for first player in general.
Green starter sucks, Black is really good, especially for second player. Nothing too surprising so far, I think.
1 Like
If green sucks it’s worth noting no one has used blue starter in a tournament that I can remember. I bet someone has but I just don’t remember.
1 Like
Well, we’ll see how Green does once I’ve added more tournament data. When I start looking at interaction with spec choices, it might do well if paired with a more aggressive hero/spec.
You could always use the deck you’ve been playing me with.
I would argue my recent random deck has ALMOST got synergy… but its still probably not even B list. Or I am just bad at it 
That said, I am toying with the idea of how to get people to play more with the blue starter. There has to be some kind of deck that makes the blue starter at least a little competitive.
I’ve just added match data for CAMS 2017 to the spreadsheet, and will add some more over the next few days. I’ve also added stuff to the model, so I’ll put up a results update soon. In the meantime, go and look at @vengefulpickle’s work here on applying a similar model to Yomi match data, if you haven’t already.
3 Likes
Long post incoming
I’ve now added CAPS 2017. I’m not going to announce every addition, but I thought this one is worth mentioning, because with EricF and Shax both using the Blue starter in that tournament, we now have data, however scant, for all of the starter decks! Nothing for Bashing, though.
Let’s do a proper update.
Model structure
What’s the model currently accounting for?
- First-player (dis)advantage
- Player skill, which can be affected by whether they’re player 1 or 2
- Starter deck strength, affected by player position
- Spec strength, affected by player position
What’s it not accounting for?
- Player skill changing over time
- Synergies, or lack of, between specs and starters - all four parts of a deck are considered in isolation
- Effect on player skill of opponent, deck used (e.g. familiarity with their deck
- Effect on deck strength of opposing deck
Of these, the starter/spec interactions are probably going to have the biggest effect, so I’ll be adding that next time.
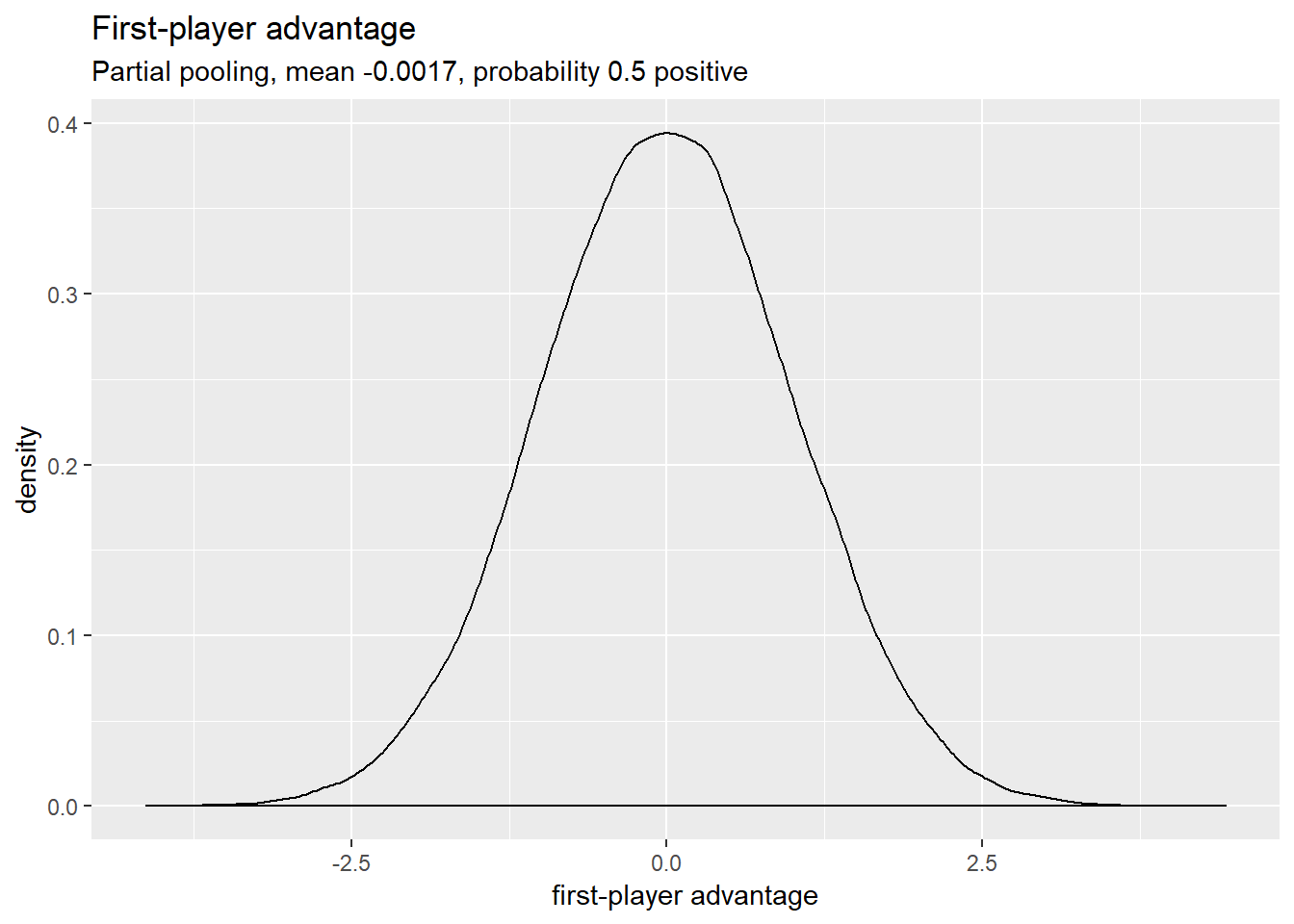
Prior choice: what do model predictions look like before adding data?
The model should make reasonably sane predictions before the data added, so we’re not waiting for 20 years for enough data for the model to make useful conclusions. Here’s what the distributions for first-turn advantage looks like:
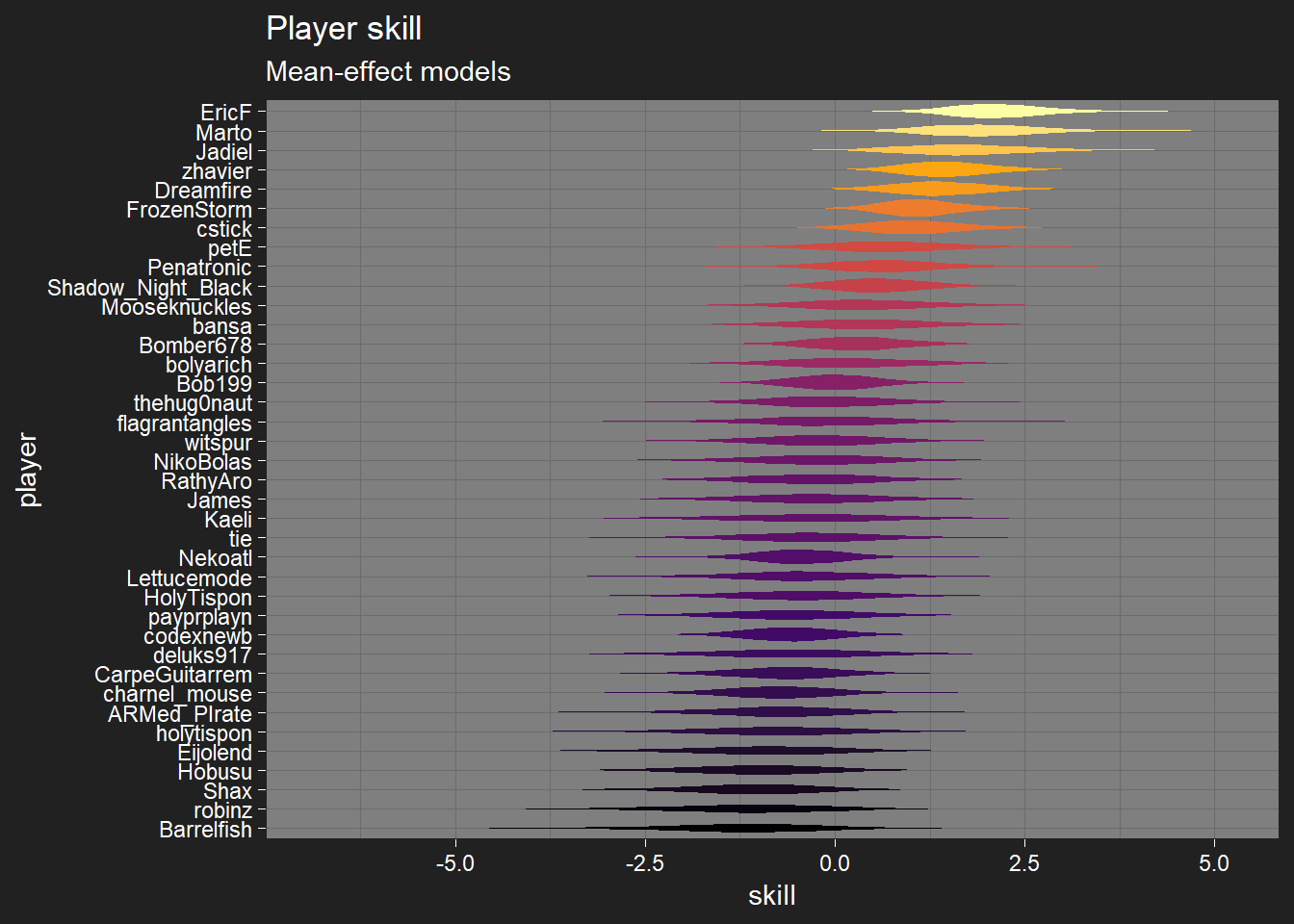
And here’s what the player skill distributions look like (players are interchangeable here):
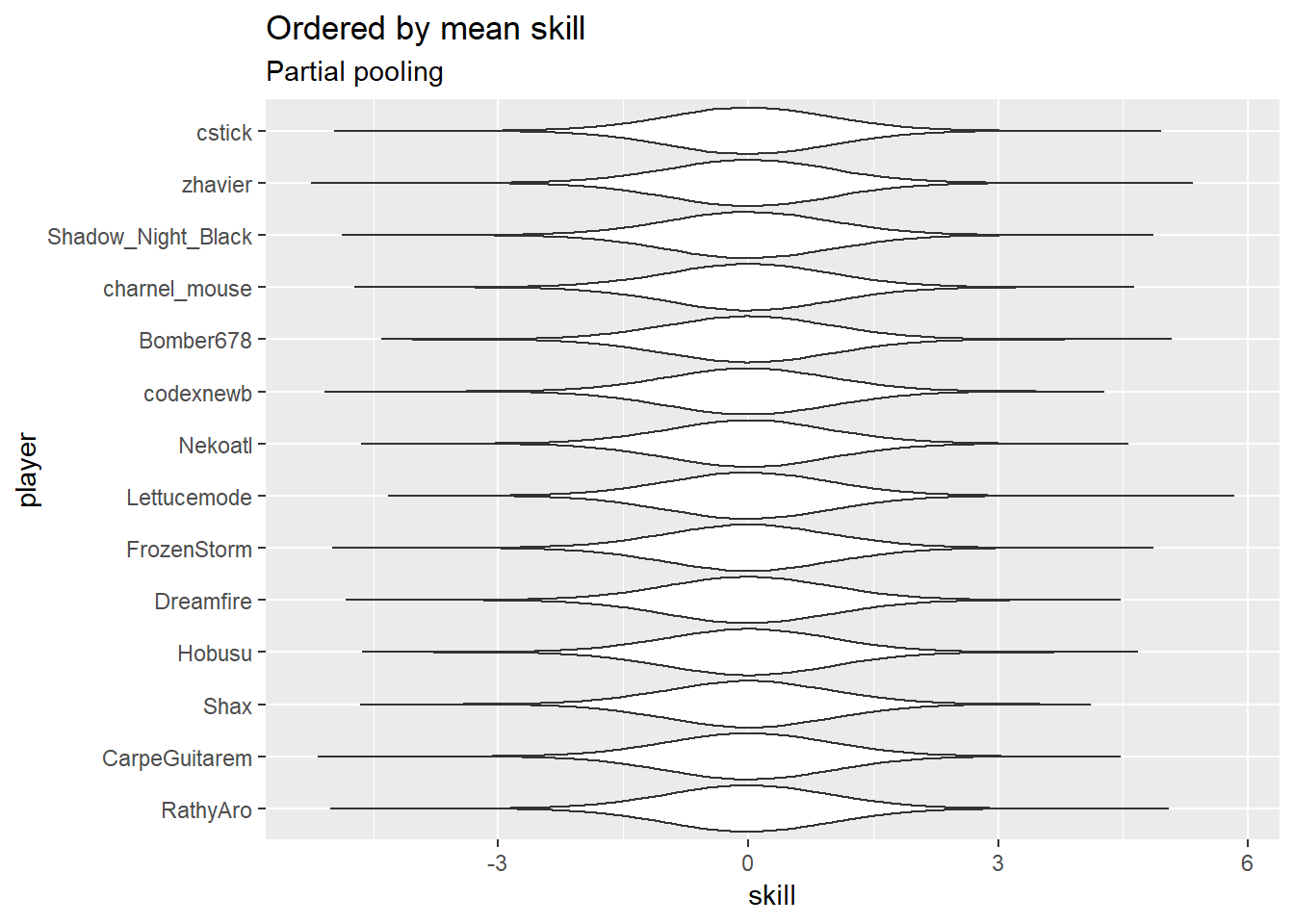
Prior distributions for starter and deck strengths are the same as for player skills.
For reference, first-player advantage, player skill, and deck strength are adjustments to the log-odds of winning. Log-odds look roughly like this:
| Victory log-odds | Victory probability |
|---|---|
| -2.20 | 0.1 |
| -1.39 | 0.2 |
| -0.85 | 0.3 |
| -0.41 | 0.4 |
| 0.00 | 0.5 |
| 0.41 | 0.6 |
| 0.85 | 0.7 |
| 1.39 | 0.8 |
| 2.20 | 0.9 |
Player skills, and the rest, are mostly in the log-odds range from -2 to 2. That’s pretty swingy, but not completely implausible, so these priors aren’t too bad. I’d rather be under- than over-certain.
I don’t care. Show me the results.
OK, OK.
Turn order
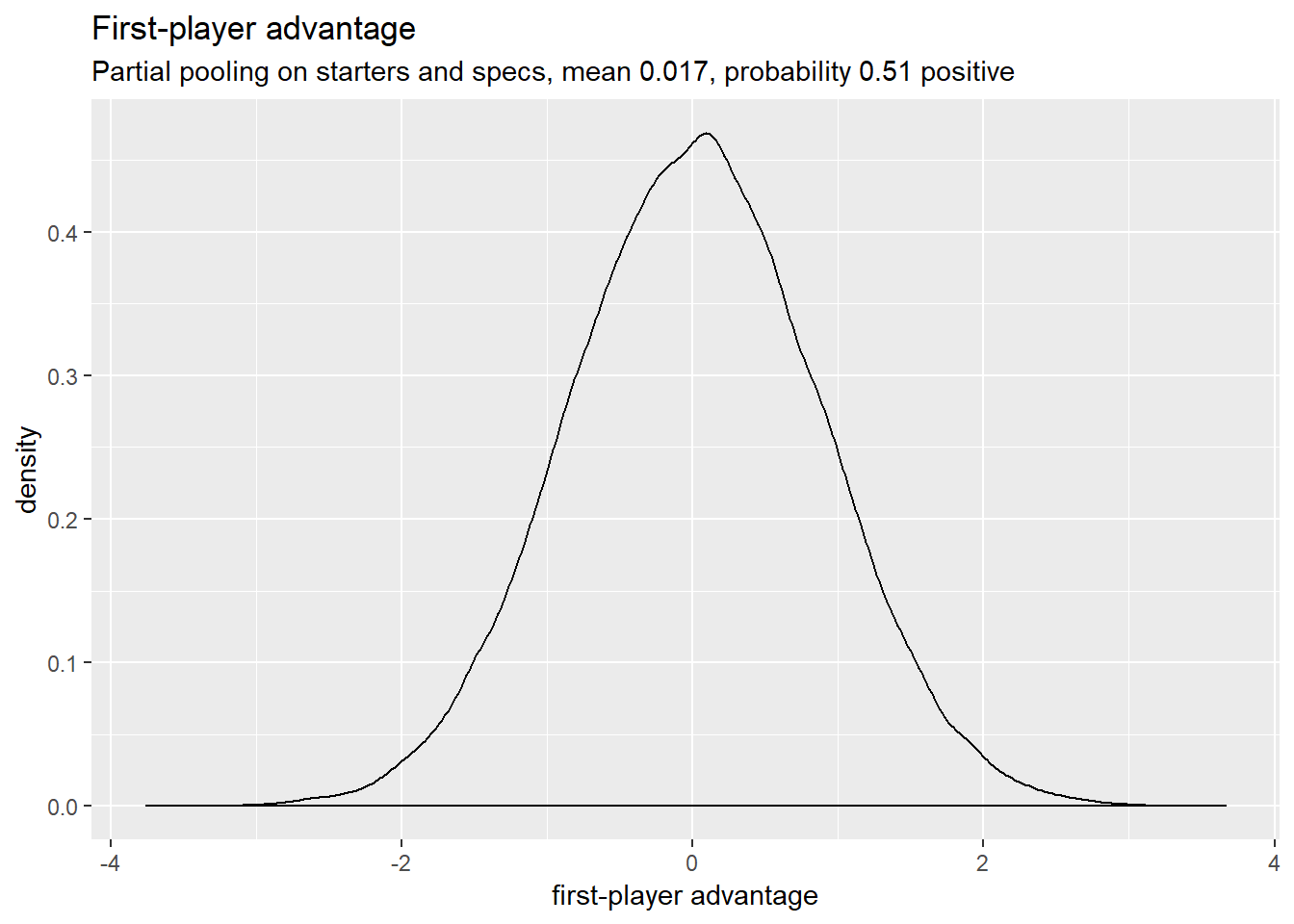
Player order makes no discernible difference. Maybe a slight advantage to player 1.
Player skill
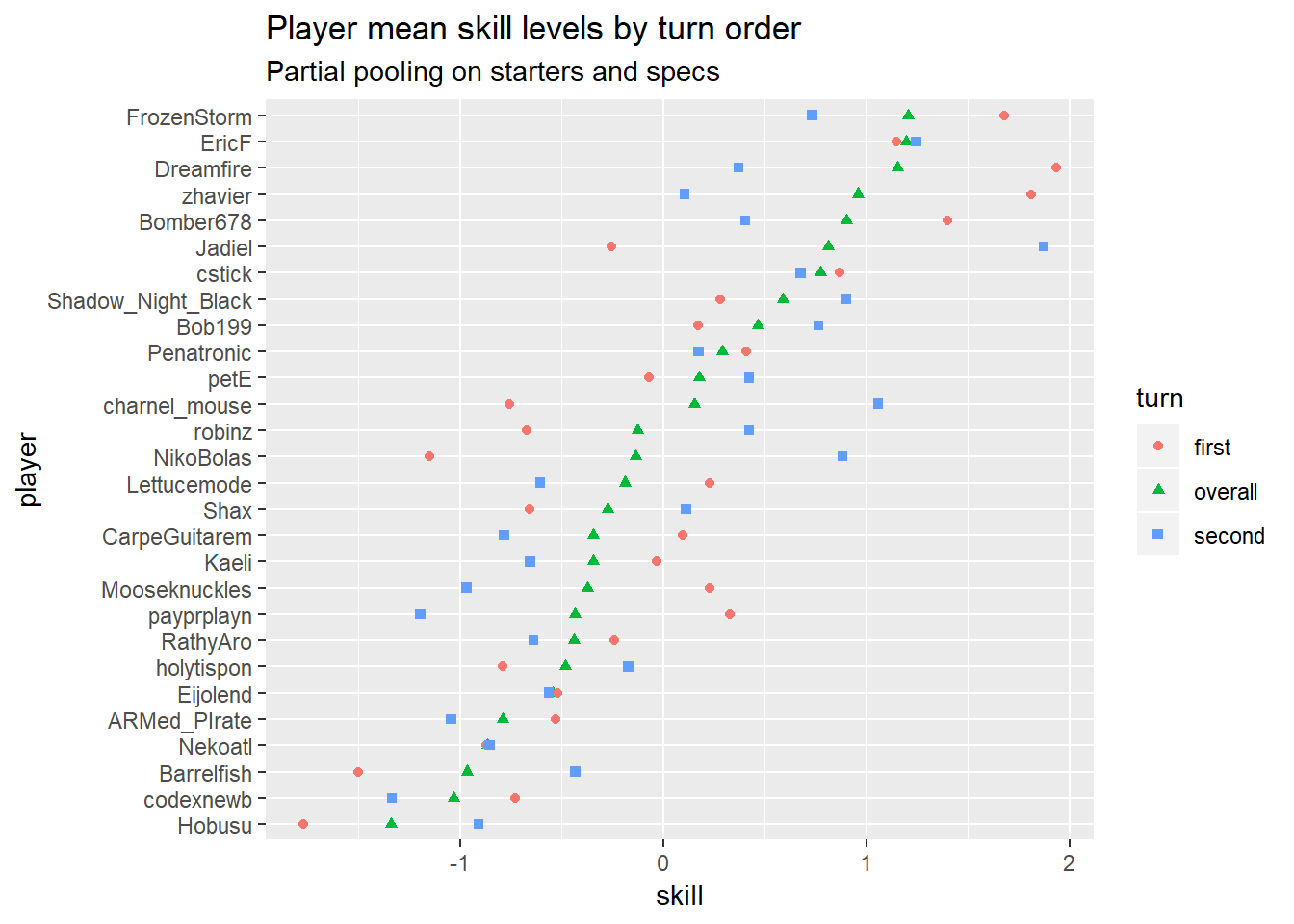
I have no idea what to make of the player skill predictions, given how many of these players vanished before I got here  The top few players look about right, I’m not so sure about the rest. There are a few players who are automatically in the middle because they haven’t played enough in these tournaments for the model to get much information on their skill level (e.g. Kaeli, with a single non-timeout match), so that will throw the ordering off what might be expected.
The top few players look about right, I’m not so sure about the rest. There are a few players who are automatically in the middle because they haven’t played enough in these tournaments for the model to get much information on their skill level (e.g. Kaeli, with a single non-timeout match), so that will throw the ordering off what might be expected.
I also have plots giving the probability each player is the best. This is the one for overall skill, I have plots by turn order too if people want them. These plots take account of uncertainty where the average skill plots don’t, so these are probably more helpful.

The two highest-ranking players are only at about 16% each of being the best, so the rankings could still change dramatically with more data.
Deck strength
Here are the starter decks:
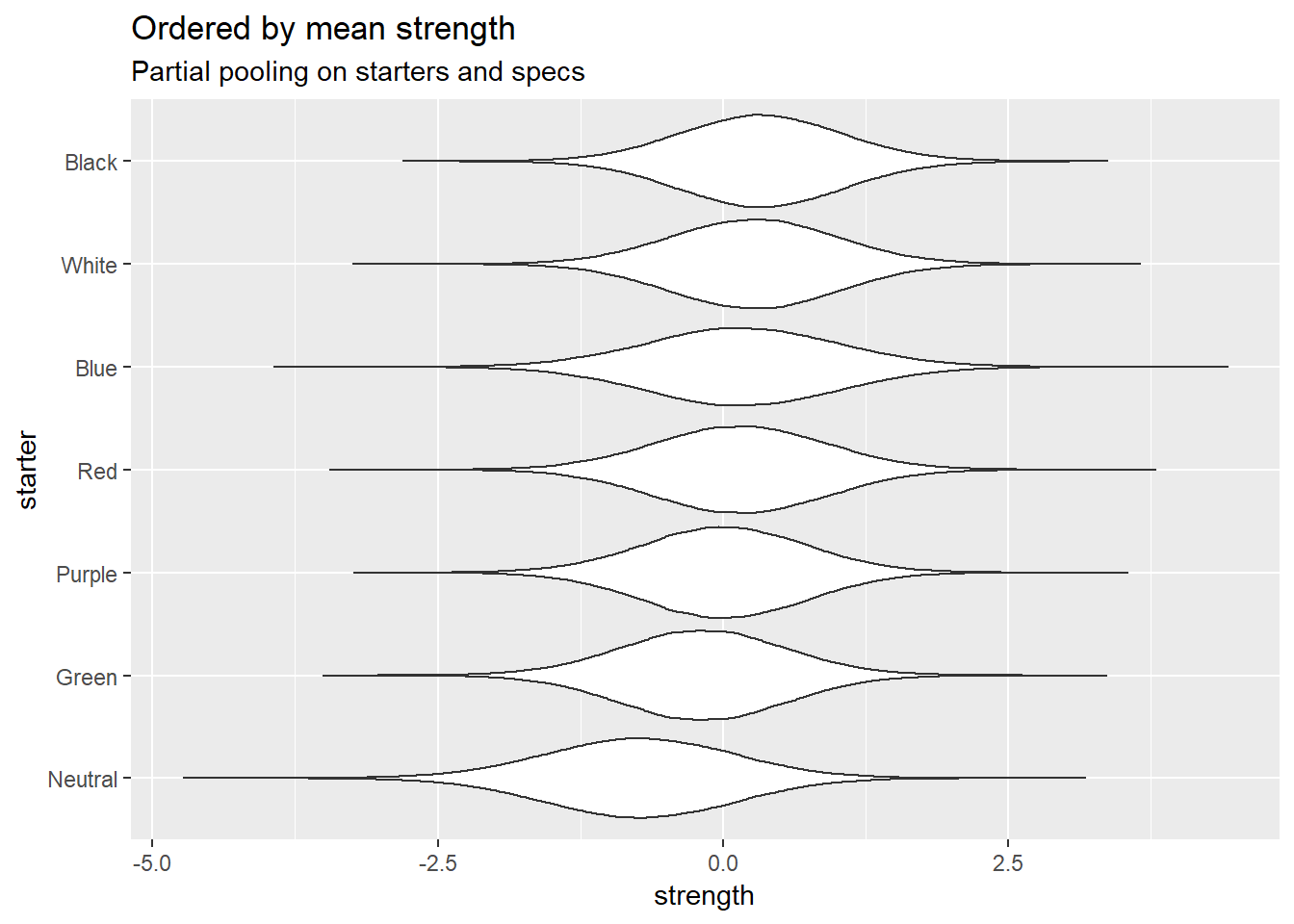

Neutral starter does really badly here.
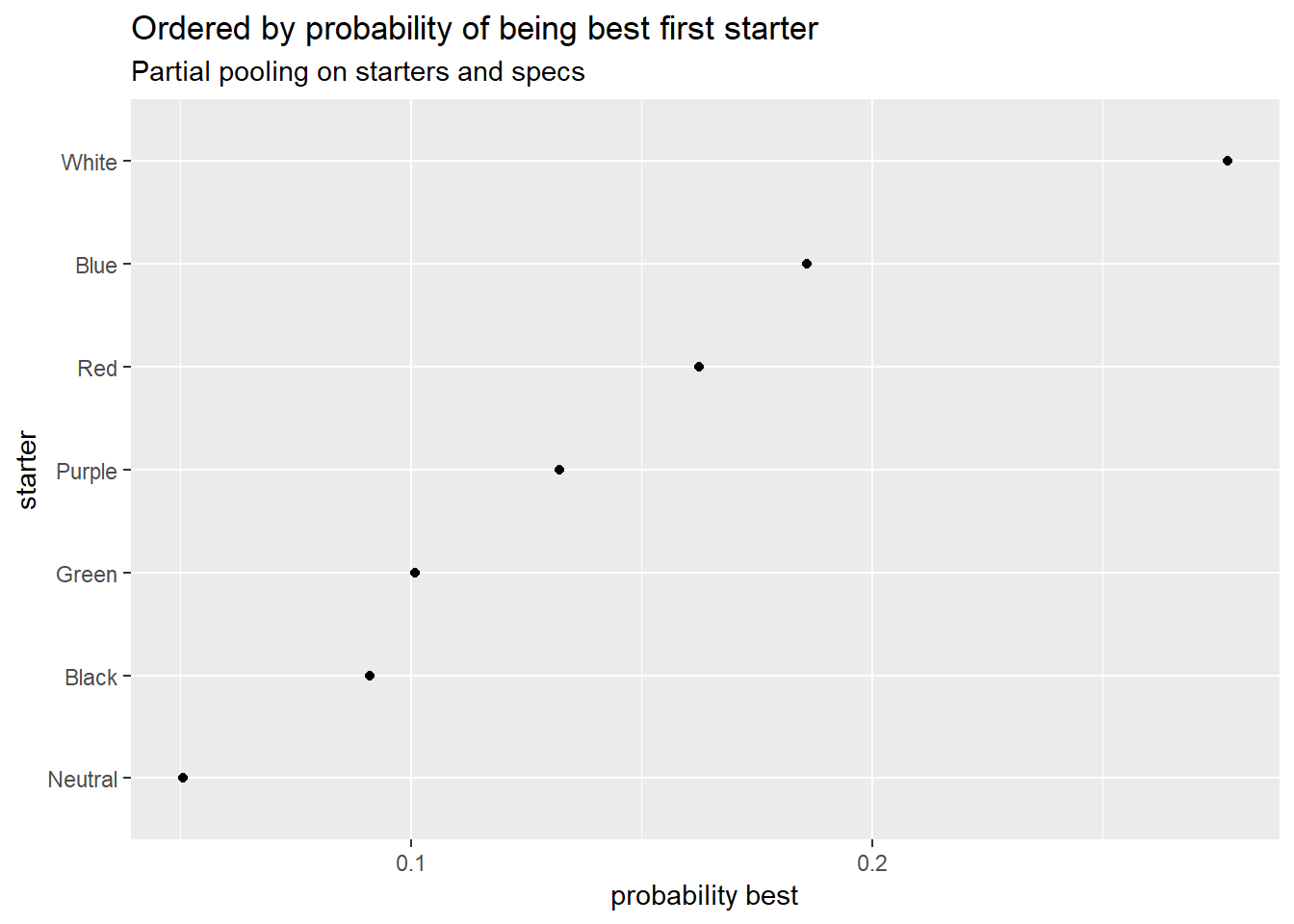
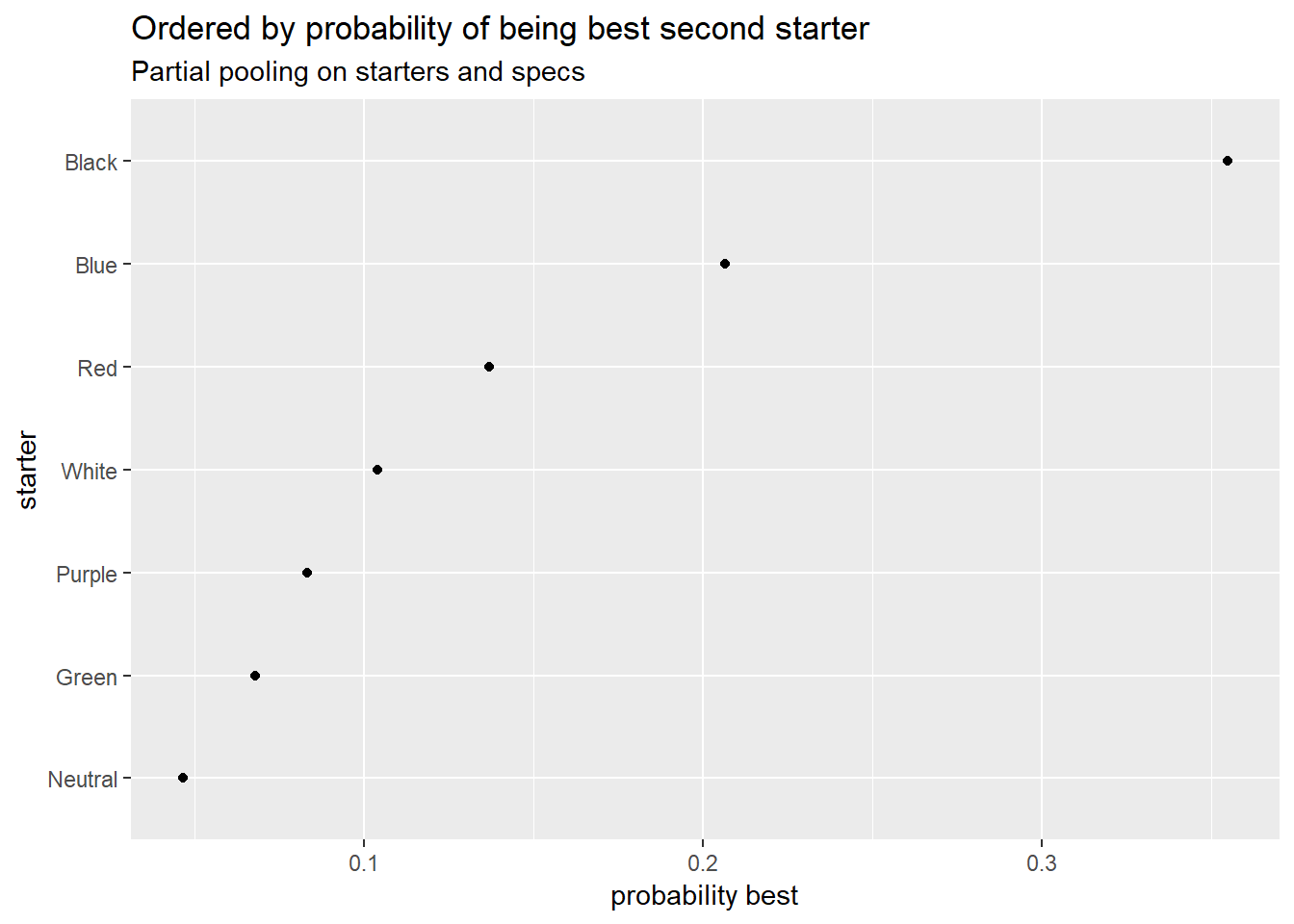
Yeah, I’m not too convinced by these at the moment. Bear in mind these are evaluations of the starters independent of the specs they’re paired with, but they still look pretty odd.

Now for the specs.
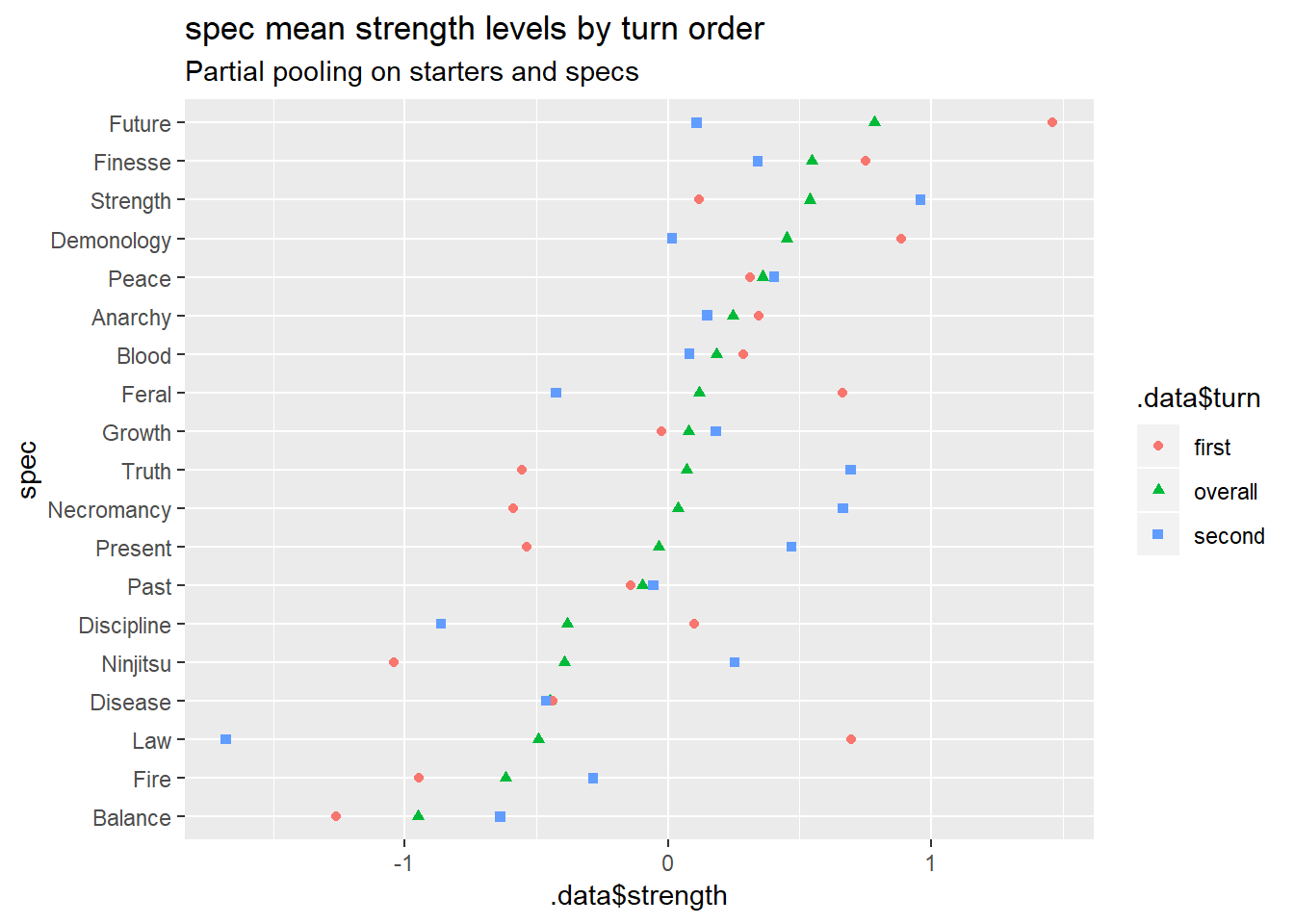
These look like a mess at the moment, too, so I’m going to skip over the other spec plots and move on to matchup predictions.
How much should we trust these results?
Well, you’ve probably looked at the starter and spec results and decided not very much. I’d like something to evaluate the model with in addition to the opinion of the players, even if that takes priority. Therefore, I’ve asked the model for post-hoc predictions for the outcome of all the matches. This is cheating a bit, because I’m using the data used to fit the model to evaluate, but it should give a rough idea of how it’s doing.
First of all, we can look at the matches where the model didn’t think a match would go the way it did. Here’s the top 10 “upsets” in the model’s opinion.
| Match | Modelled probability of outcome |
|---|---|
| CAMS 2018 FrozenStorm Nightmare vs. zhavier Miracle Grow , won by zhavier | 0.29 |
| CAPS 2017 zhavier Miracle Grow vs. EricF Peace/Balance/Anarchy , won by EricF | 0.32 |
| CAPS 2017 FrozenStorm Nightmare vs. petE Miracle Grow , won by petE | 0.36 |
| CAMS 2018 cstick Finesse/Present/Discipline vs. RathyAro Nightmare , won by cstick | 0.39 |
| CAPS 2017 Penatronic Present/Peace/Blood vs. robinz Discipline/Fire/Truth , won by robinz | 0.40 |
| CAMS 2018 RathyAro Nightmare vs. Nekoatl Demonology/Strength/Growth , won by RathyAro | 0.44 |
| CAPS 2017 Jadiel Feral/Future/Truth vs. EricF Peace/Balance/Anarchy , won by Jadiel | 0.47 |
| CAMS 2018 zhavier Miracle Grow vs. Dreamfire Demonology/Strength/Growth , won by Dreamfire | 0.47 |
| CAMS 2018 zhavier Miracle Grow vs. FrozenStorm Nightmare , won by zhavier | 0.48 |
| CAMS 2017 Shadow_Night_Black Feral/Present/Truth vs. zhavier Discipline/Present/Anarchy , won by Shadow_Night_Black | 0.49 |
I haven’t had time to actually read through the matches, so if you have opinions about how unexpected these results are, let me know! What’s worth mentioning is that, out of the 108 matches I’ve current recorded, these are the only 10 matches where the model put the probability of the given outcome at less than 50%. A lot of the rest were thought to be pretty lopsided:

Now, we expect these to be thought of as lopsided to some extent: these are the matches used to fit the model, so it should be fairly confident about predicting them. So here’s a finer breakdown, where we roughly compare the model’s predicted outcome to how often it actually happened:

It looks like the model’s predicted matchups aren’t lopsided enough! The matchups are even more extreme than it thinks they are.
What’s next?
This is where the model is at right now. It’s got some promise, I think, but it desperately needs, as a bare minimum, more data, and to take account of starter/spec synergies before its skill/strength results are really reliable.
Current plans
Next I’ll be allowing for starter/spec pairings to have an effect on deck strength, in addition to their individual effects. Hopefully we’ll see decks like Nightmare and Miracle Grow rapidly climb to the top of the charts.
I also need to add more match data. I don’t want to go too far back in time yet, because then the change in player skills over time will become something I need to worry about, so I’ll be adding results from the LDT series first.
Anything I can help with that doesn’t involve understanding the statistics spiel?
The most helpful thing I could get right now is anything odd on the current results set that I haven’t picked up on. I know the deck evaluations are a bit weird. Feedback on the current player ranking would be nice, if it won’t start fights. Most immediately helpful would be thoughts on the top 10 upsets list, as currently ranked by the model. Do these match results seem particularly surprising, in hindsight? Would you expect them to go the same way if they were played again?
Stop filling the forums up with so many images
If that’s a problem, I can just put the model up on GitHub, and occasionally bump the thread when I do a big update. Unless I get told otherwise, I’ll just post images for now.
Show me the stats!
Stan model code
data {
int<lower=0> M; // number of matches
int<lower=0> P; // number of players
int<lower=0> St; // number of starter decks
int<lower=0> Sp; // number of specs
int<lower=1> first_player[M]; // ID number of first player
int<lower=1> second_player[M]; // ID number of second player
int<lower=1> first_starter[M]; // ID number of first starter deck
int<lower=1> second_starter[M]; // ID number of second starter deck
int<lower=1> first_specs1[M]; // ID number for first player's first spec
int<lower=1> first_specs2[M]; // ID number for first player's second spec
int<lower=1> first_specs3[M]; // ID number for first player's third spec
int<lower=1> second_specs1[M]; // ID number for second player's first spec
int<lower=1> second_specs2[M]; // ID number for second player's second spec
int<lower=1> second_specs3[M]; // ID number for second player's third spec
int<lower=0, upper=1> w[M]; // 1 = first player wins, 0 = second player wins
}
parameters {
real turn; // first-player advantage in log odds
vector[P] player_std; // player skill levels in log odds effect
vector[P] player_turn_std; // player skill level adjustment for going first (penalty if second)
vector[St] starter_std; // starter deck strengths
vector[St] starter_turn_std; // starter deck strength adjustment for going first (penalty if second)
vector[Sp] spec_std; // spec strength
vector[Sp] spec_turn_std; // spec strength adjustment for going first
real lsd_player; // player skill log spread
real lsd_player_turn; // player skill turn adjustment log spread
real lsd_starter; // starter deck strength log spread
real lsd_starter_turn; // starter deck strength turn adjustment log spread
real lsd_spec; // spec strength log spread
real lsd_spec_turn; // spec strength log turn adjustment spread
}
transformed parameters{
vector[M] matchup; // log-odds of a first-player win for each match
real<lower=0> sd_player = exp(lsd_player);
real<lower=0> sd_player_turn = exp(lsd_player_turn);
real<lower=0> sd_starter = exp(lsd_starter);
real<lower=0> sd_starter_turn = exp(lsd_starter_turn);
real<lower=0> sd_spec = exp(lsd_spec);
real<lower=0> sd_spec_turn = exp(lsd_spec_turn);
vector[P] player = sd_player * player_std;
vector[P] player_turn = sd_player_turn * player_turn_std;
vector[St] starter = sd_starter * starter_std;
vector[St] starter_turn = sd_starter_turn * starter_turn_std;
vector[Sp] spec = sd_spec * spec_std;
vector[Sp] spec_turn = sd_spec_turn * spec_turn_std;
matchup = turn +
player[first_player] + player_turn[first_player] - player[second_player] + player_turn[second_player] +
starter[first_starter] - starter[second_starter] + starter_turn[first_starter] + starter_turn[second_starter] +
spec[first_specs1] - spec[second_specs1] + spec_turn[first_specs1] + spec_turn[second_specs1] +
spec[first_specs2] - spec[second_specs2] + spec_turn[first_specs2] + spec_turn[second_specs2] +
spec[first_specs3] - spec[second_specs3] + spec_turn[first_specs3] + spec_turn[second_specs3];
}
model {
lsd_player ~ normal(0, 0.1);
lsd_player_turn ~ normal(0, 0.1);
lsd_starter ~ normal(0, 0.1);
lsd_starter_turn ~ normal(0, 0.1);
lsd_spec ~ normal(0, 0.1);
lsd_spec_turn ~ normal(0, 0.1);
turn ~ std_normal();
player_std ~ std_normal();
player_turn_std ~ std_normal();
starter_std ~ std_normal();
starter_turn_std ~ std_normal();
spec_std ~ std_normal();
spec_turn_std ~ std_normal();
w ~ bernoulli_logit(matchup);
}
What's this "partial pooling" you're referring to in the plot subtitles?
Partial pooling is a statistical technique often used by Stan users, and people who read the work of Andrew Gelman, and is a type of hierarchical model.
As an example, I previously had all the player skill levels modelled as independent. That gives reasonable results, but partial pooling lets me control how large the levels can get, and also introduces some dependency.
Specifically, whereas before each skill level had an independent Normal(0, 1) distribution, they now all have an independent Normal(0, sd) distribution, where sd is an additional unknown parameter for the model to do inference on (these are the lsd_... and sd_... variables in the Stan model code above). So, if a player’s skill is considered to be large, then sd will be pushed to be larger, and the other player skill will tend to spread out a bit more too. Statistically, this has a “shrinkage” effect, that stops any of the estimated skill/strength levels from becoming infeasible large at the expense of everything else.
This is useful for two other reasons. Firstly, the use of an sd variable means that first-player advantage, player skill, starter strength etc. can now have a different average size of effect. If the sd for player skill tends to be larger, that means player skill is considered to tend to have a larger effect on matchup compared to first-turn advantage. Secondly, sd for e.g. player skill determines the general population that the modelled players’ skill levels are drawn from. This means that inference on sd translates to inference on what we expect the skill level of non-modelled players to look like. Has a new player just appeared? sd will help give an a priori idea of what their skill level might look like.
It’s called partial pooling in comparison to, e.g., modelling all player skill levels as exactly the same (complete pooling), or treating them all independently (no pooling).
5 Likes
I don’t think I’m in the running for fourth best player, so something feels strange there.
Well, your only tournament data I’ve got at the moment is CAMS this year, and you did well there. That’s the only data for me at the moment, once I’ve added XCAFS I expect my rating to tank.
1 Like
This is super interesting stuff @charnel_mouse, I appreciate the obvious abundance of effort you’re putting in here!
I think labeling the player graph based on “skill” feels a bit weird though; I feel like perhaps it’s weighting results too high without accounting for deck strength (or perhaps as you pointed out, there’s just too little data). Hobusu, Nekoatl and codexnewb in particular feel very out of place on that chart near the bottom (they are plenty skilled), and I am definitely not a better player than Zhav or EricF (and probably Dreamfire).
Nevertheless, this is super cool stuff, thanks for sharing!
2 Likes
Thanks @FrozenStorm! Good to hear people are finding this interesting, and not being put off by the post length.
I agree those players are ranked pretty low at the moment. That’s partly the number of matches, but it’s also because I’ve only got three tournaments’ worth. That means the players, at most, are being observed with three different decks, usually less, so the model is struggling with sufficiently disentangling player skill from deck strength. I think “skill” is the correct term, because the model is at least trying to account for deck strength and turn advantage, just not well enough yet.
3 Likes
The work you are doing here is amazing.
How big of a data sample your model would need to be meaningful?
I could try to scrounge for local history of games from reports and provide maybe 30-50 games between a few regulars.
There are exactly zero players from local scene who also play on the forum so far, so no possibility for cross-reference, sadly.
But could still be used as a context for comparing decks.
Blue has much more spotlight here, i.e.
4 Likes
Hey, thanks. I honestly have no idea how much more data it needs. It definitely needs more deck variety per player, but I can’t put any numbers to that.
If you want to add games to the sheet, please do! I’m going to change the format at some point, but if you put “Offline play” or something in the tournament column, it should be good!
2 Likes
Can you change the format ASAP? I’d suggest something like
start_year tournament round player1 player2 victor victory starter spec1 spec2 spec3
Disjointing deck from event seems necessary. Would allow to record casual matches.
Edit: I think I’ll go ahead and start filling out the file with this format, and you can adapt to it when convenient, unless you’d have it differently.
Edit2: Wait no, I can’t record both player’s deck in the same row that way. Damn.
Edit3: I guess we have to implement Match ID keyfield of sorts? Or stick to one match = one row and make extra 4 fields for second deck?
Yeah, go for it. I’m working off a local version of the sheet rather than the online version, so it doesn’t screw up anything I’m doing.
If it’s easier, put in the decks in the forum’s format, e.g. [Demonology/Necromancy]/Finesse. I think I’m going to have a separate sheet that R can use as a key to derive the specs and starter from that. Then just have a deck1 and a deck2 column for each match, so it’s all on a single row.
I hadn’t gotten as far as thinking about keyfields, to be honest. I’ve only been looking at tournament matches, so it hasn’t come up. If you think it helps, go for it.
2 Likes
@charnel_mouse I could help out with entering the MMM data for mono-color results, if that’s at all worth adding.
1 Like
Yeah, that would really helpful, thank you!
I’ve tried some more complex version of the model, but it didn’t seem to make much difference to the results – if anything, it made the predictive performance worse. At this point, the thing I need most is more data. I’ll keep plugging away at adding results from the Seasonal Swiss tournaments.
I’ve also rejigged the format of the main data file, so that it’s hopefully easier to add match data:
- Deck information for each player is now done per match.
- Instead of giving deck information in 4 columns (starter, 3 specs), there’s now a single column for the deck’s name in forum format, e.g. [Balance]/Blood/Strength. I’ll go through and standardise the deck names. Just make sure the slashes are there, and the first spec is one for the starter deck. For example, Balance/Strength/Growth with the Green starter is fine, Strength/Balance/Growth with the Green starter is not. You don’t need the brackets. Alternatively, you can add a deck’s nickname to the nickname sheet, and enter that instead. I’ve already added some common ones: MonoRed etc., Nightmare, Miracle Grow, and some others.
- There’s also a new column for match format (forum/Tabletopia/face-to-face), so I can start using the data kindly collected by Metalize.
- There’s an optional column to indicate that the player order in a match is unknown. If it’s known, just leave it blank.
If there’s anything else that you think would make entry easier, please let me know.
Current to-do list includes adding more match data, and maybe putting my modelling work up on GitHub so people can laugh at my terrible Stan code see the details if they’re curious.
3 Likes
Another quick update. I’m still working on this, slowly.
I’ve now added interactions between starter decks and specs, and between specs, to account for synergies. It’s improved the model’s post-hoc predictions on match results a little. I don’t think it’s currently worth a full post yet, because it still has a problem the previous versions had that I didn’t mention before. Here are the model’s rankings for the monocolour decks, low rank is better. See if you can spot the problem.
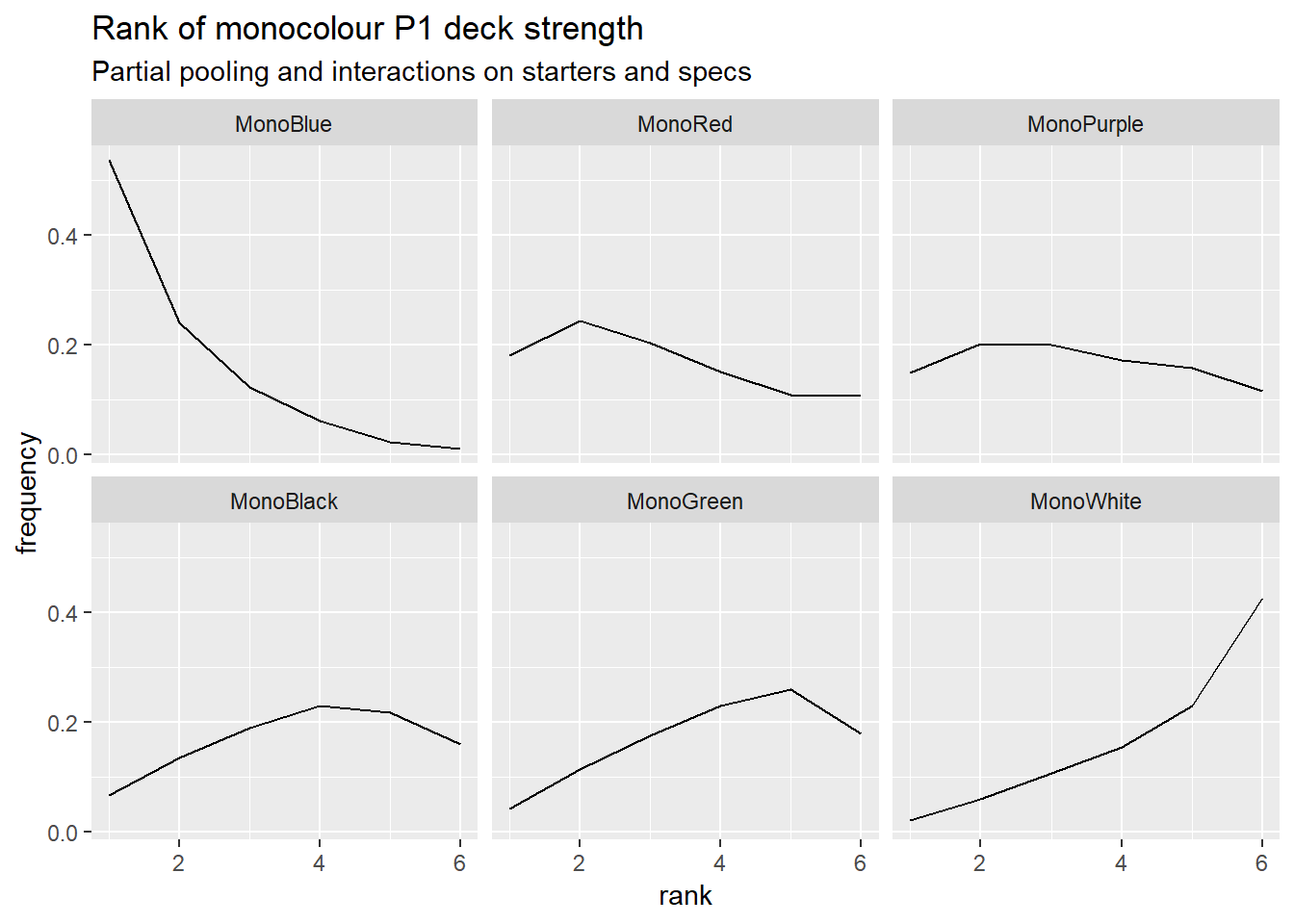
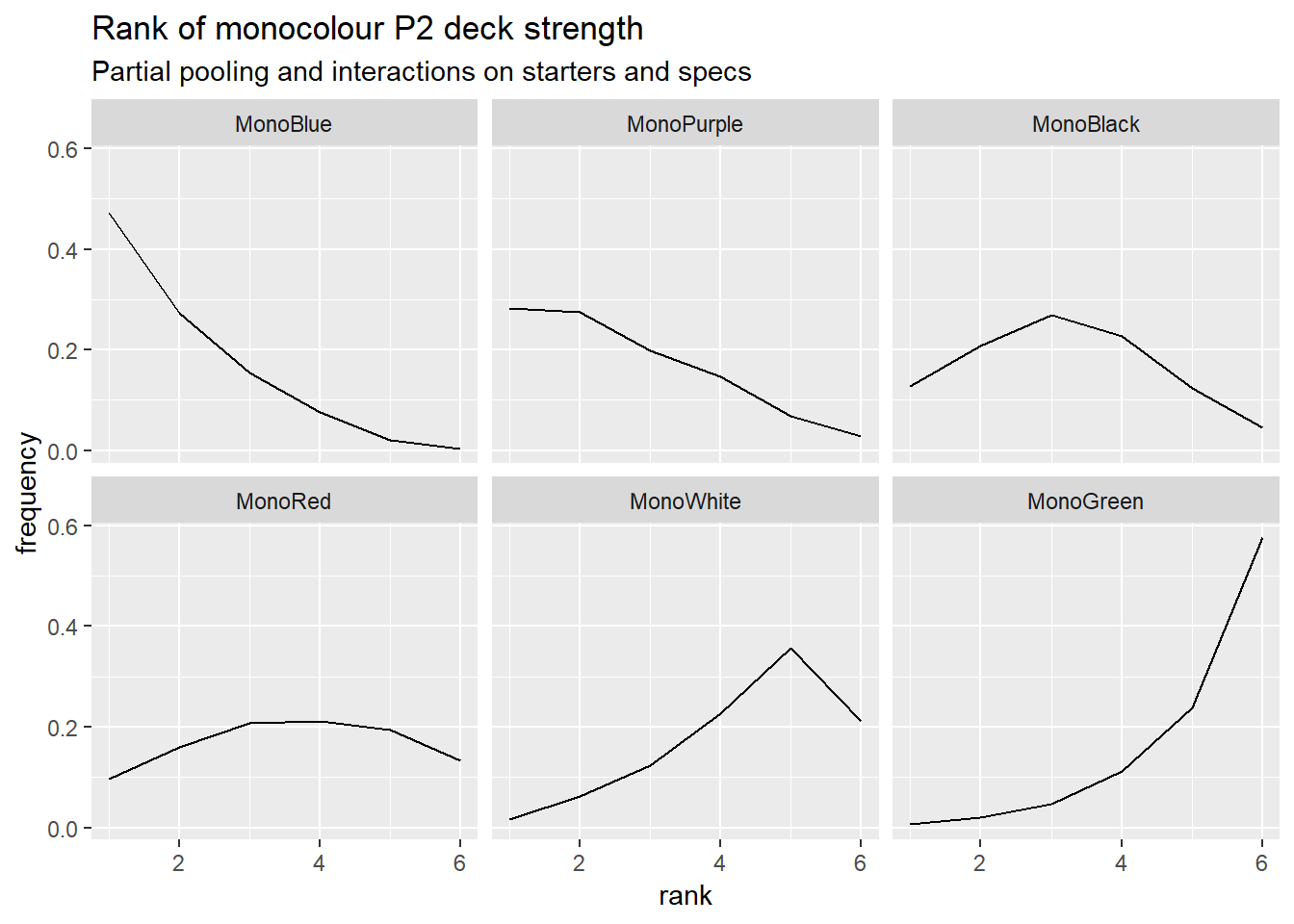
I think I need to let a deck’s strength be dependent on which deck it’s facing. Full-length post next time if that sorts things out.
1 Like
OK, I fixed the problem, but it was nothing to do with the model. It was because I’d misrecorded the Black vs. Blue MMM1 matches as all being won by Blue. Ho, ho, ho. I know what I’m doing.
I’ve changed the model anyway, so here’s another update. Not as thorough as last time, my brain’s a bit burnt-out at the moment.
Data status
I’ve added match results for CAWS18 and XCAPS19. I’m leaving CAMS19 results until the tournament finishes. In the meantime, I’ll get the model to predict CAMS19 match results from previous data to see how well it does, and post about it after the tournament’s over.
Model structure
Previously, each deck (or starter, or spec) was assigned a single strength value, so the decks were effectively ranked on a one-dimensional scale. In hindsight, this wasn’t very likely to work well: the strength of a deck is going to depend on the opposing deck.
For example, Nightmare ([Demonology/Necromancy]/Finesse) is a very strong deck, but isn’t so great against Miracle Grow ([Anarchy]/Growth/Strength). Similarly, the usefulness of a particular spec in your deck depends on what you’re facing. Going for a Growth deck for Might of Leaf and Claw? Probably not so great against specs with upgrade removal and/or ways to easily deal with Blooming Ancients. Some specs are a lot stronger than others, but they aren’t no-brainers that are great against everything. Well, most of them aren’t. ![]()
I’ve therefore complected the model to only work in terms of opposing pairs. Starter vs. starter, starter vs. spec, spec vs. spec. As before, these each have an additive effect on the log-odds of a player-one victory.
Player skills are still treated individually, not in opposed pairs: I think ranking players on a simple scale makes sense. Also, the main goal here is to evaluate deck strengths, so I’d like to keep player effects simple so I can worry about more important things.
New results
Turn order
I’m no longer tracking first-player advantage. It’s now effectively part of the deck strengths, because, e.g., Red vs. Green is tracked separately from Green vs. Red (P1 component first).
Player skill
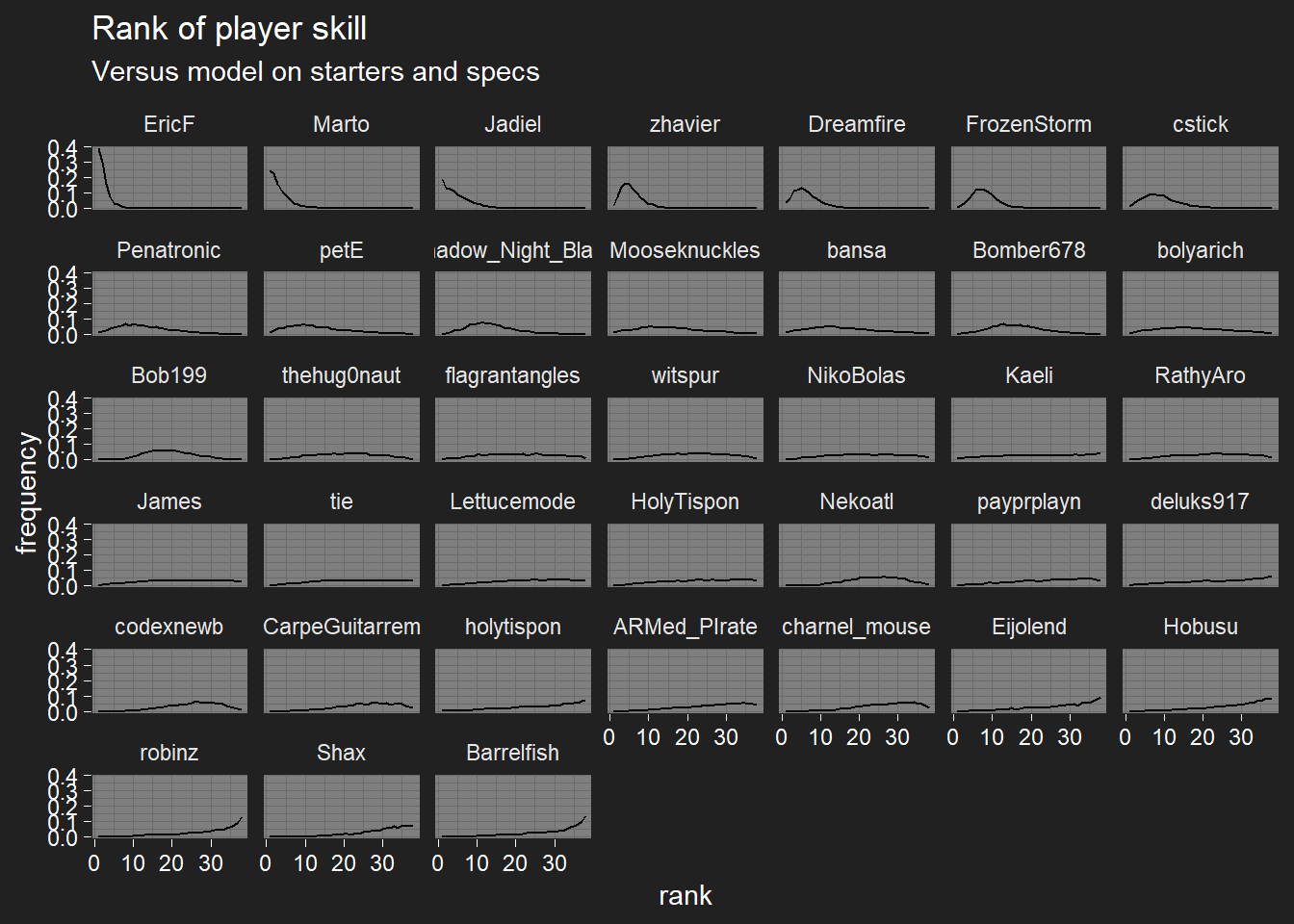
I’ve removed turn-order effects from player skill for the moment, so I can focus more on deck effects. Skills are on the log-odds-effect scale.
I’ve also switched to plotting each player’s rank distribution instead of just their probability of being the best player, hopefully it’s a bit more informative.
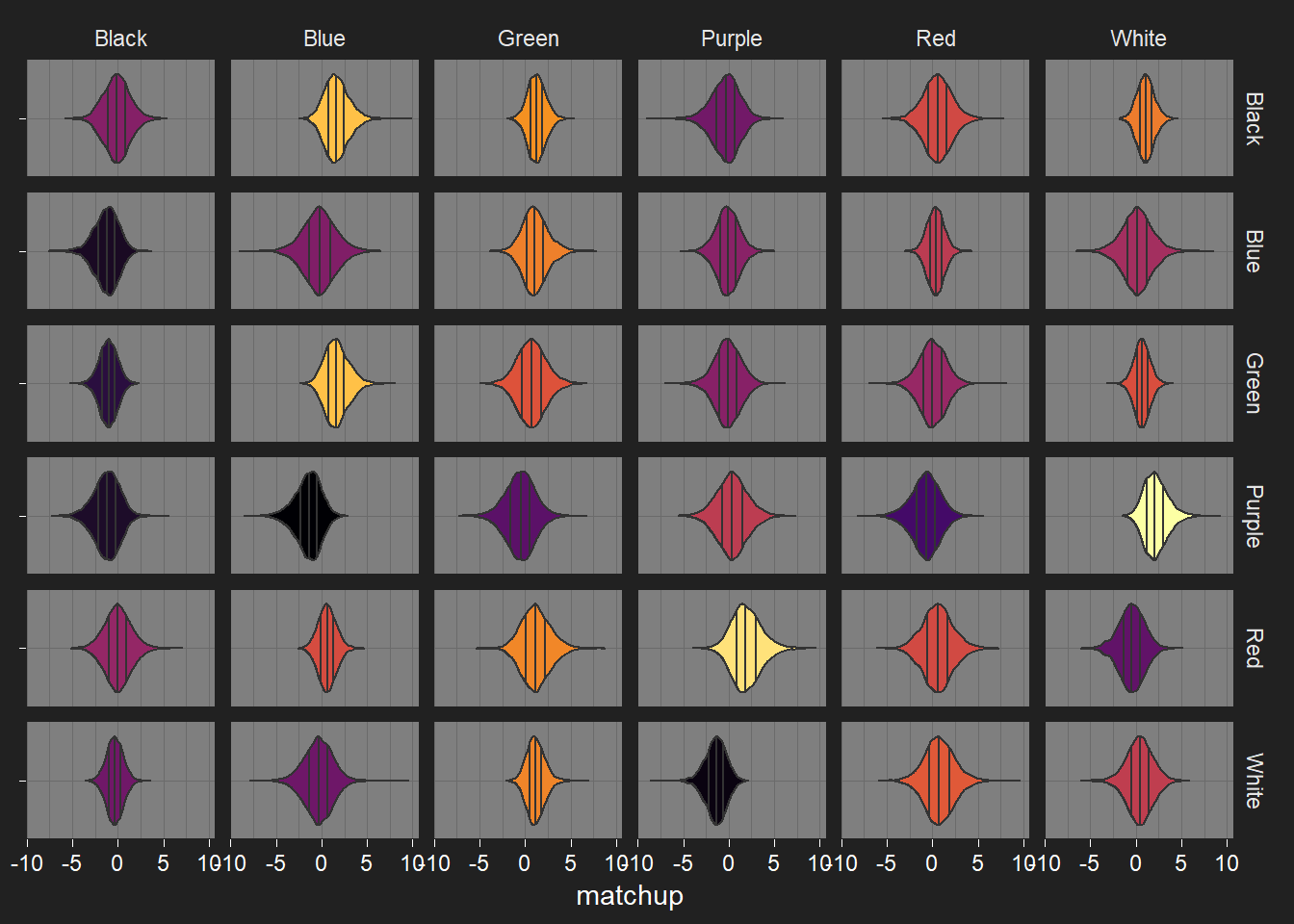
Deck strengths
Because of the switch to looking at opposed pairs, plots showing the strengths for all the different components are now incredibly ungainly. Because of this, I’m just posting the predicted matchups between the monocolour decks, and can put up matchups for other decks later (the ones with a nickname, perhaps). Player 1 on the rows, Player 2 on the columns.

Numeric summaries for the matchups below. I’ll put up a similar table for the recorded matches used to fit the model, when I’ve got the time.
Numerical monocolour matchup details
I’m not entirely sure how useful this table is going to be in a Discourse post: in my IDE this is a DataTable, so I can easily sort by different columns. I’ve sorted them by matchup fairness here.
P1/P2 deck are the monocolour decks used. Matchup is the average P1 win probability, written in the x–(10-x) matchup notation that’s used in Yomi. Fairness depends on how far the average P1 win probability is from the perfectly-balanced 50% win probability: a 5-5 matchup has fairness 1, 0-10 and 10-0 matchups have fairness 0.
| Match ID | P1 deck | P2 deck | P1 win probability | matchup | fairness |
|---|---|---|---|---|---|
| 25 | Red | Black | 0.498 | 5.0-5.0 | 1.00 |
| 17 | Green | Red | 0.506 | 5.1-4.9 | 0.99 |
| 10 | Blue | Purple | 0.479 | 4.8-5.2 | 0.96 |
| 16 | Green | Purple | 0.479 | 4.8-5.2 | 0.96 |
| 1 | Black | Black | 0.474 | 4.7-5.3 | 0.95 |
| 12 | Blue | White | 0.524 | 5.2-4.8 | 0.95 |
| 8 | Blue | Blue | 0.467 | 4.7-5.3 | 0.93 |
| 4 | Black | Purple | 0.447 | 4.5-5.5 | 0.89 |
| 32 | White | Blue | 0.441 | 4.4-5.6 | 0.88 |
| 22 | Purple | Purple | 0.563 | 5.6-4.4 | 0.87 |
| 31 | White | Black | 0.428 | 4.3-5.7 | 0.86 |
| 11 | Blue | Red | 0.577 | 5.8-4.2 | 0.85 |
| 36 | White | White | 0.576 | 5.8-4.2 | 0.85 |
| 30 | Red | White | 0.416 | 4.2-5.8 | 0.83 |
| 21 | Purple | Green | 0.412 | 4.1-5.9 | 0.82 |
| 5 | Black | Red | 0.600 | 6.0-4.0 | 0.80 |
| 29 | Red | Red | 0.598 | 6.0-4.0 | 0.80 |
| 15 | Green | Green | 0.622 | 6.2-3.8 | 0.76 |
| 23 | Purple | Red | 0.379 | 3.8-6.2 | 0.76 |
| 26 | Red | Blue | 0.629 | 6.3-3.7 | 0.74 |
| 35 | White | Red | 0.628 | 6.3-3.7 | 0.74 |
| 18 | Green | White | 0.641 | 6.4-3.6 | 0.72 |
| 9 | Blue | Green | 0.692 | 6.9-3.1 | 0.62 |
| 27 | Red | Green | 0.691 | 6.9-3.1 | 0.62 |
| 13 | Green | Black | 0.296 | 3.0-7.0 | 0.59 |
| 19 | Purple | Black | 0.295 | 3.0-7.0 | 0.59 |
| 6 | Black | White | 0.713 | 7.1-2.9 | 0.57 |
| 7 | Blue | Black | 0.282 | 2.8-7.2 | 0.56 |
| 33 | White | Green | 0.723 | 7.2-2.8 | 0.55 |
| 3 | Black | Green | 0.744 | 7.4-2.6 | 0.51 |
| 20 | Purple | Blue | 0.256 | 2.6-7.4 | 0.51 |
| 34 | White | Purple | 0.245 | 2.5-7.5 | 0.49 |
| 2 | Black | Blue | 0.780 | 7.8-2.2 | 0.44 |
| 14 | Green | Blue | 0.782 | 7.8-2.2 | 0.44 |
| 28 | Red | Purple | 0.796 | 8.0-2.0 | 0.41 |
| 24 | Purple | White | 0.846 | 8.5-1.5 | 0.31 |
Model code
Comments might be out of date, take with a pinch of salt.
Stan code
data {
int<lower=0> M; // number of matches
int<lower=0> P; // number of players
int<lower=0> St; // number of starter decks
int<lower=0> Sp; // number of specs
int<lower=1> first_player[M]; // ID number of first player
int<lower=1> second_player[M]; // ID number of second player
int<lower=1> first_starter[M]; // ID number of first starter deck
int<lower=1> second_starter[M]; // ID number of second starter deck
int<lower=1> first_specs1[M];
int<lower=1> first_specs2[M];
int<lower=1> first_specs3[M];
int<lower=1> second_specs1[M];
int<lower=1> second_specs2[M];
int<lower=1> second_specs3[M];
int<lower=0, upper=1> w[M]; // 1 = first player wins, 0 = second player wins
}
parameters {
vector[P] player_std; // player skill levels in log odds effect
matrix[St, St] starter_vs_starter_std; // starter vs. starter effect in log odds
matrix[St, Sp] starter_vs_spec_std; // starter vs. spec effect in log odds
matrix[Sp, St] spec_vs_starter_std; // spec vs. starter effect in log odds
matrix[Sp, Sp] spec_vs_spec_std; // spec vs. spec effect in log odds
real<lower=0> sd_player; // player skill spread
real<lower=0> sd_starter_vs_starter; // starter vs. starter effect spread
real<lower=0> sd_starter_vs_spec; // starter vs. spec effect (or vice versa) spread
real<lower=0> sd_spec_vs_spec; // spec vs. spec effect spread
}
transformed parameters {
vector[M] matchup; // log-odds of a first-player win for each match
vector[P] player = sd_player * player_std;
matrix[St, St] starter_vs_starter = sd_starter_vs_starter * starter_vs_starter_std;
matrix[St, Sp] starter_vs_spec = sd_starter_vs_spec * starter_vs_spec_std;
matrix[Sp, St] spec_vs_starter = sd_starter_vs_spec * spec_vs_starter_std;
matrix[Sp, Sp] spec_vs_spec = sd_spec_vs_spec * spec_vs_spec_std;
for (i in 1:M) {
matchup[i] = player[first_player[i]] - player[second_player[i]] +
starter_vs_starter[first_starter[i], second_starter[i]] +
starter_vs_spec[first_starter[i], second_specs1[i]] +
starter_vs_spec[first_starter[i], second_specs2[i]] +
starter_vs_spec[first_starter[i], second_specs3[i]] +
spec_vs_starter[first_specs1[i], second_starter[i]] +
spec_vs_starter[first_specs2[i], second_starter[i]] +
spec_vs_starter[first_specs3[i], second_starter[i]] +
spec_vs_spec[first_specs1[i], second_specs1[i]] +
spec_vs_spec[first_specs1[i], second_specs2[i]] +
spec_vs_spec[first_specs1[i], second_specs3[i]] +
spec_vs_spec[first_specs2[i], second_specs1[i]] +
spec_vs_spec[first_specs2[i], second_specs2[i]] +
spec_vs_spec[first_specs2[i], second_specs3[i]] +
spec_vs_spec[first_specs3[i], second_specs1[i]] +
spec_vs_spec[first_specs3[i], second_specs2[i]] +
spec_vs_spec[first_specs3[i], second_specs3[i]];
}
}
model {
sd_player ~ lognormal(0, 0.5);
sd_starter_vs_starter ~ lognormal(0, 0.5);
sd_starter_vs_spec ~ lognormal(0, 0.5);
sd_spec_vs_spec ~ lognormal(0, 0.5);
player_std ~ std_normal();
for (i in 1:St) {
starter_vs_starter_std[i, ] ~ std_normal();
starter_vs_spec_std[i, ] ~ std_normal();
}
for (i in 1:Sp) {
spec_vs_starter_std[i, ] ~ std_normal();
spec_vs_spec_std[i, ] ~ std_normal();
}
w ~ bernoulli_logit(matchup);
}
Where to go from here?
Main items on the current to-do list:
- Put some more thought into the prior distributions for the variance parameters. The new model structure makes more intuitive sense, I think, but I need to check it has the same prior as the other models, so I can check it’s better at matchup prediction.
- More data. CAMS19 when it finishes, but first I’m planning to integrate the data that @Metalize kindly put together (sorry for the delay!). I’m delaying adding data from older tournaments (i.e. the old forum), because I currently don’t account for player skills changing over time. This does shaft currently forum-inactive players like Hobusu, unfortunately.
- Evaluate the average influence of player skill vs. deck strength on the matchup. In theory, I can already do this, but my current plots aren’t as clear as I’d like them to be, so I need to tidy them up a bit before I put them up.
- Interaction terms between the opposed pairs. The thought of coding this fills me with dread, honestly, but without them the model currently doesn’t take account of inter-spec synergies at all.
- At some point I tried a different model, where the player skills were between 0 and 1, and were a multiplicative effect on the deck strength. This failed, but it might have been because of the Black vs. Blue issue I’ve now fixed. I think this is worth doing eventually, for the same reasons I suggested it for the Yomi model: it means that the model gives deck strengths under optimal play, instead of deck strengths under average play, and the former is what we’re more interested in.
- Tier lists! The end goal, really. This is a bit harder now decks aren’t rated on a single scale, but I can plug all the available decks into a zero-sum game, see how frequently they’re picked at the Nash equilibrium, and use that as their rating. I want to do more checks on the model’s predictive performance before I do this.
- There’s some other “cool” things I’d like to try once the model’s doing well. For example, I could pull up the predicted matchups in the Seasonal Swiss tournaments, and see whether the matches tend to become fairer in later rounds. My model’s also similar enough in structure to professional systems (Élő, Glicko, Trueskill) that I could try taking my model’s conclusions and showing how they’d work out under those other systems. For example, the variance parameters are analogies to TrueSkill’s beta parameter, that describes the height of a game’s skill ceiling (the Factor #2 section here).
- Anything else? Anything stand out as unusual in the monocolour matchups? (Purple vs. White stands out to me). Other matchup predictions you’d like to see? Does my Stan code suck? Yes, it does.
2 Likes